
Seznam kapitol
Po včerejším povídáním o dekódování a Out-of-Order zpracování se dnes zaměříme na výpočetní část, práci s pamětí, prefetch, termální management a konečně i na spekulativní vykonávání instrukcí. Věděli jste, že Core je silně zaměřen na multimediální aplikace?
První část povídání o architektuře Core je k dispozici
.
Výpočetní jednotky
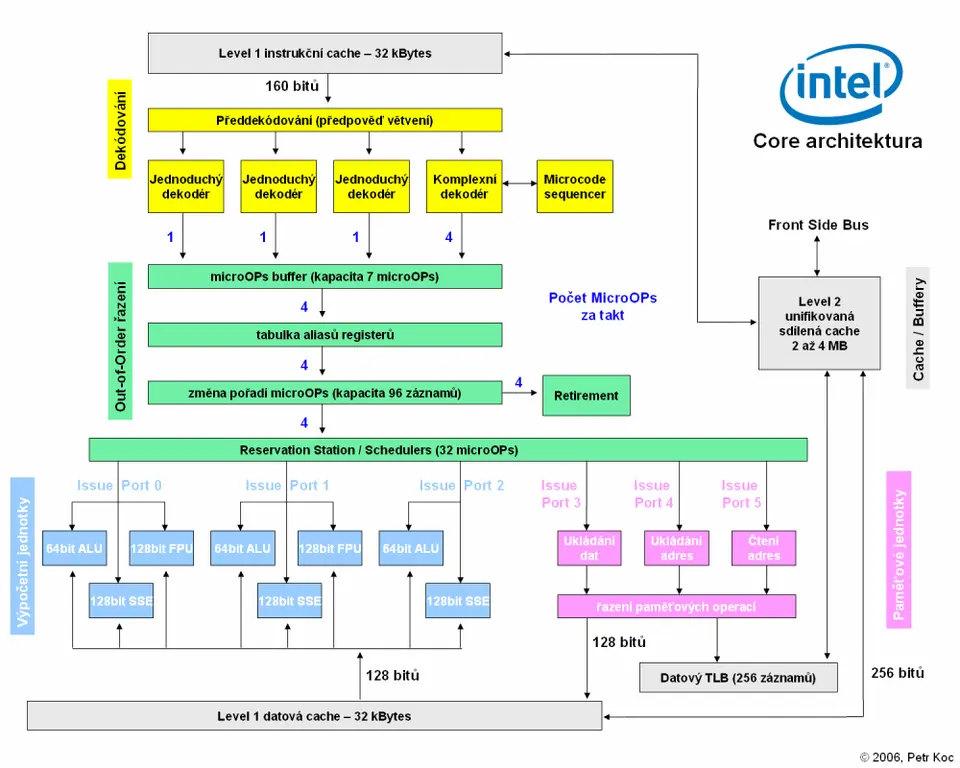
Protože Core má širší pipeline o rychlosti čtyř microOPs za cyklus, musely být do návrhu přidány další výpočetní jednotky. Oproti Pentiu M tak přibyla jedna jednotka pro celočíselné výpočty a jedna SSE jednotka.

Výpočetní část tak tvoří tři celočíselné skalární jednotky (ALU), dvě FPU s možností vektorování SSE instrukcí pracujícíh s desetinnou čárkou a tři celočíselné SSE jednotky. Z nich některé jsou specializované a umí operace, které jiné neumí. Tyto jednotky jsou uspořádány do třech Issue Portů:
Port 0
- komplexní ALU, FPU / SSE jednotka a celočíselná SSE jednotka
Port 1
- jednoduchá ALU, FPU / SSE, celočíselná SSE jednotka
Port 2
- jednoduchá ALU a celočíselná SSE
Issue Port je místem, do kterého se posílají microOPs z Reservation Station. V rámci každého Issue Portu operuje v jednom okamžiku pouze jediná jednotka, které lze odeslat jedinou microOP. Pozicování jednotek na jednotlivé Issue Porty a počet samotných Issue Portů jsou tak klíčové faktory pro dosahování optimálního paralelismu.
Uspořádání jednotek na Issue Porty je v Core provedeno poměrně dobře a to vždy tak, aby každý typ jednotky měl svůj Issue Port. V praxi tak každá celočíselná jednotka ALU je na vlastním Issue Portu, tudíž Core může v každém cyklu zaměstnat až tři ALU jednotky. Stejně je na tom u celočíselných SSE operací. Celkový výkon při zpracování celých čísel tak může být, zejména pokud je prováděn vektorově, gigantický.
Menšího zlepšení bylo dosaženo také při zpracování čísel s desetinnou čárkou. Jednotky pro výpočet x87 instrukcí jsou sice stále jen dvě, na druhou stranu vektorovací SSE operace s čísly s desetinnou čárkou byly i zde rozšířeny z původních 64 bitů na 128 bitů za takt. Core tak zvyšuje rychlost v situaci s vektorováním na dvojnásobek. Přes toto zlepšení lze ale říct, že Core není nijak intenzivně na čísla s desetinnou čárkou zaměřen. Konkurenční Athlon má totiž hned tři FPU jednotky. Je ale vidět, že v procesoru je určitý prostor pro další zvyšování výkonu - stačilo by na Issue Port 2 přidat další FPU / SSE jednotku a výkon by byl vynikající. Proč toto Intel neudělal, mi není známo. Je možné, že celkové předělání FPU jednotky by bylo příliš složité a další transistory by způsobovaly větší zahřívání. V každém případě výkon čipu ani v operacích s čísly s desetinnou čárkou nebude nijak tragický a pokud aplikace využije vektorovací verzi (tj. SSE), mohl by Core dosahovat nejvyššího výkonu ze všech v současnosti provozovaných architektur.
Jednotky pro práci s pamětí
Vyjma výpočetních jednotek je pipeline architektury Core tvořena také jednotkami pro načítání a ukládání informací.

Konkrétně se zde nachází tři jednotky, přičemž každá má svůj vlastní Issue Port. Celkově tak Core obsahuje celkem šest Issue Portů, zatímco Pentium M jich má pět a NetBurst dokonce pouze čtyři. Jedna jednotka se stará o ukládání dat, druhá o ukládání adres a třetí o načítání adres.
Tyto jednotky pracují s gigantickým datovým Translation Look-Aside Bufferem o kapacitě 256 záznamů. To je 8x více než má NetBurst a Athlon 64 a dvakrát více, než má Pentium M.
Translation Look-Aside Buffer (TLB) slouží jako vyrovnávací paměť (cache) mezi převodem virtuálních adres na adresy fyzické. Virtuální adresy jsou ty adresy, které vidí program - tedy například rozsah 00000000h až 007FFFFFh. Tyto adresy (lépe řečeno datové bloky) ale mohou být v paměti umístěny nikoli lineárně, ale zcela náhodně - například adrese 007FFFFFh by mohla odpovídat reálná adresa v paměti RAM 00000126h. Stejně tak mohou jiné virtuální adresy odpovídat místům ve swap file (paměti, kterou operační systém vytváří na pevném disku a která supluje nedostatek paměti RAM). Převodní tabulka mezi virtuální a reálnou adresou se nazývá page table. Části této tabulky může procesor uložit do svého Translation Look-Aside Bufferu, čímž významně urychlí získání reálné adresy. Čím více záznamů TLB má, tím větší šance na úspěch.
Tři jednotky určené k práci s pamětí ukládají a čtou z TLB příslušné adresy. Dále také ukládají data do datové L1 cache o velikosti 32 kByte. Její rychlost Intel nezveřejnil, pravděpodobně se ale jedná o cache s přístupovou dobou tři hodinové cykly (optimistické odhady hovoří dokonce o dvou cyklech). Komunikace s těmito cache probíhá přes Memory Reorder Buffer, který určuje pořadí čtení a zápisu tak, aby se paměti nezatěžovaly operacemi, které mohou počkat.
Schéma z architektury Core je velmi podobné schématu z procesoru Pentium M. Prakticky zde došlo jen k malým změnám. Jednou z nich je zdvojnásobení datových šířek. Spoj mezi Memory Reorder Bufferem a cache je nyní 128bit. Díky tomu je možné uložit celý 128bit SSE vektor v jednom hodinovém cyklu. Stejně tak byla rozšířena datová šířka mezi datovou L1 cache a Reservation Station (neboli mezi cache a výpočetními jednotkami ALU, FPU a SSE). Opět na 128bit. Toto rozšíření bylo nezbytné kvůli novým SSE jednotkám s datovou šířkou 128bitů - jakákoli menší šířka by procesor značně zpomalovala, neboť by výpočty mohly probíhat rychleji, než by bylo možné dodávat potřebná data.
























