

Seznam kapitol
Dnešní článek uzavře naši rozpravu na téma budoucí architektury AMD v oblasti grafických jader. Graphics Core Next nahradí současnou architekturu AMD použitou u Radeonu HD 6900, ale nebude dříve než v roce 2013.
AMD Graphics Core Next - jaké může být?
V
jsme si probrali Compute Unit jako základní výpočetní celek, ale ona sama není GPU. Stejně jako v případě starších architektur je podobných celkově více a v blocích tvoří GPU. I zde budou platit nějaká pravidla a Compute Unit se budou sdružovat v celcích, které AMD pojmenovalo CU Array. V budoucnu je tedy předpokladem u dalších generací této architektury n polí o 4 Compute Units.
Compute Units suplují funkčnost dosavadních stream procesorů v SIMD Caymanu. Nyní se tedy podíváme, co nám do finálního jádra ještě zbývá a jakou mají dané jednotky funkčnost. Ilustrační obrázky ale je nutné brát s rezervou, protože ještě není takto architektura, respektive samotný čip, hotová a ani neexistují žádné prototypy a bavíme se zde opravdu v teoretické rovině.
Začneme u paměti a cache, které budou v čipu přítomny. AMD Graphics Core Next. Architektura podporuje 64 kB nebo 128 kB L2 cache pro každý paměťový řadič, což dává při obvyklém počtu (4) 64bitových řadičů 512 kB L2 cache. Koherentní L2 cache zde funguje tak, že všechny Compute Units vidí stejná data a je tak ušetřen neefektivní a řádově pomalejší přístup k běžné video paměti akcelerátoru kvůli synchronizaci dat. Synchronizace mezi procesorem a GPU bude prováděna na úrovni L2 cache, kde bude nutné zajistit a udržet koherentnost dat mezi těmito dvěma jednotkami kvůli následnému rozdělení úloh mezi CPU a GPU. V případě APU Llano je to vyřešeno vysokorychlostní sběrnicí mezi oběma integrovanými jádry a není potřeba této velké L2 cache, která zabírá podstatnou část plochy jádra.
AMD má v případě Graphics Core Next a řízení výpočetních operací k dispozici také jednotky zvané
Asynchrounous Compute Engines
. Jejich základní funkčnost tkví v přijetí toho, co se má zpracovat a přerozdělení práce mezi Compute Utnits. Graphics Core Next je schopno pracovat na několika různých úlohách současně a právě ACE jsou schopna rozhodovat o alokaci zdrojů nebo prioritě jednotlivých úloh. Prozatím nevíme, jak se jednotky ACE budou chovat v případě několika souběžně zpracovávaných úloh.
ACE jednotky mají v případě architektury Graphics Core Next význam i kvůli omezeným možnostem zpracovávání úloh „out-of-order“. V minulých kapitolách jsme si řekli, že Graphics Core Next je klasickou „in-order“ a instrukční tok nebo wavefronts nemohou být při zpracování reorganizovány. ACE ale mohou absenci „out-of-order“ částečně nahradit tím, že dokáží určité úlohy nastavit jako prioritní a jiné odsunout. To dovolí uvolnit zdroje pro úlohy, které mají byt zpracovány pokud možno co nejdříve a nenechávat rozpracované úlohy těsně před dokončením. Tento princip ale není nijak zvlášť odlišný od toho, jak moderní procesory s architekturou „in-order“ (např. Intel Atom) zvládají multi-tasking.
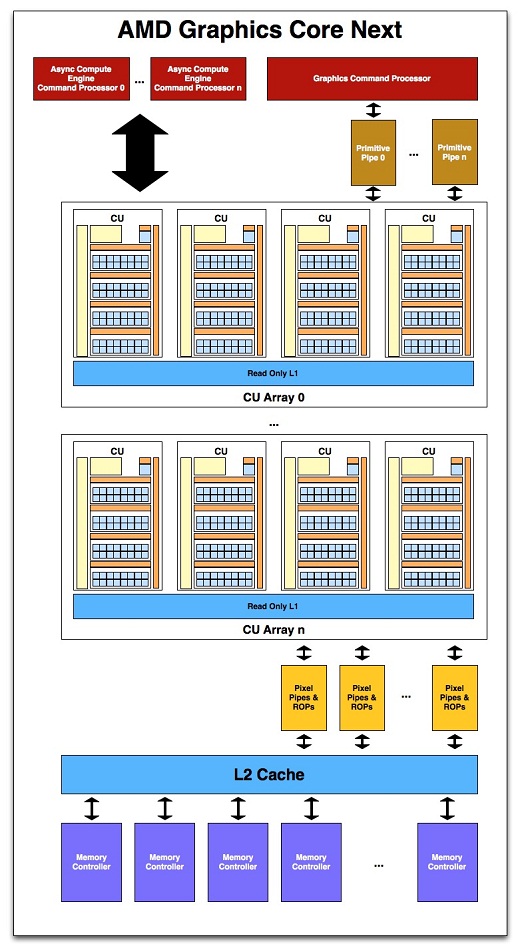
Také ovšem musíme myslet na to, že zde máme v případě Graphics Core Next i hardware pro akceleraci grafiky. V případě současné architektury VLIW4 u jádra Cayman je řídicí procesor pro grafiku na vrcholu pomyslné pyramidy a je zodpovědný za využívání různých součástí grafického subsystému čipu. Zajímavostí je fakt, že tzv. duální grafický engine, který pro Cayman přinesl zdvojení některých výpočetních jednotek (mimo jiné dvojitý geometrický engine), zde už nebude. Místo něj zde budeme mít mnoho jednoduchých pipeline, které budou sloužit k výpočtům geometrie. Tyto pipeline budou sloužit pro teselaci, geometrii nebo tzv. „high-order surface processing“, který se ale uplatní spíše ve vizualizacích než v komerčních hrách.
Architektura čipu Cayman má díky zdvojené geometrické jednotce téměř dvojnásobný výkon než předešlé čipy a velmi dotahuje náskok získaný Nvidií s architekturou Fermi. Graphics Core Next bude v tomto ohledu škálovatelné, takže teoreticky může AMD v případě potřeby získat masivní geometrický výkon, který hravě strčí do kapsy všechny současné grafické čipy.
Předchozí řádky popisovaly především Compute Units a jejich součásti. Nyní se podívejme i na velmi důležitou část čipu, kterou jsou rasterizační jednotky (ROPs). Lze očekávat, že jejich počet bude velmi úzce spjat s počtem paměťových řadičů k zachování poměru mezi ROPs L2 Cache a pamětí, což je kritické pro výkon rasterizačních jednotek.
Bohužel AMD nevypustilo o Graphics Core Next žádné podrobnější informace, pokud jde o uspořádání nebo počty jednotek grafického subsystému. AMD potřebovalo Graphics Core Next představit hlavně vývojářům APU, kteří si musí své potřeby plánovat hodně dopředu a být připravení, když na trh dorazí reálný hardware. Jak už bylo řečeno, AMD chce mít pro tuto novou architekturu reálné aplikace v momentě, kdy Graphics Core Next vypustí do světa. Podobně probíhalo také postupné odhalování v případě Nvidie a její architektury, ale AMD aspoň nemáchá maketami svých karet s prototypy nových čipů.
AMD Graphics Core Next ale přichází také s poměrně novou technologií PRT alias
Partially Resident Textures
, což znamená, že textury budou v paměti načteny pouze částečně a dovolí tak vývojářům použít větší textury bez dopadu na výkon v momentu, kdy jsou nahrávané textury příliš velké pro paměť akcelerátoru. Podobnou technologii jsme ale mohli vidět v případě her jako Qauke Wars nebo Rage, za kterými stojí John Carmack a grafické enginy id Tech 4/5. Technologie AMD je podobná, ale je implementována na úrovni hardware.











