
Seznam kapitol
Na pevné disky není spolehnutí. Tento fakt alespoň jednou pocítil snad každý uživatel PC. Sám mám na disky takovou smůlu, že za posledních asi deset let žádný nepřežil zcela bez problémů déle než jeden rok. Co vlastně stojí za všemi těmi poruchami?
S.M.A.R.T. S.M.A.R.T. je zkratka pro Self-Monitoring Analysis and Reporting Technology. Do češtiny bychom to mohli velmi volně přeložit jako samokontrolní mechanismus. Ten je integrován ve všech moderních pevných discích, přičemž "moderní" zde znamená cca. od druhé poloviny devadesátých let. Nečekejte S.M.A.R.T. na discích kapacit v řádu stovek MB či prvních "gigových" discích. Ale již třeba některé 4GB disky ho mají.
Úkolem S.M.A.R.T. je nezávisle na operačním systému či jiném hardware monitorovat stav pevného disku. Hlídají se některé základní ukazatele, jejichž pravidelným sledováním lze předpovědět problémy pevného disku. I některé těžko předvídatelné problémy se mohou projevit změnou některých vlastností - S.M.A.R.T. je dobré cca. jednou týdně zběžně prohlédnout, zda se něco nezměnilo a pokud ano, problém vyhodnotit.
Obecně novější disky hlídají více ukazatelů než disky starší - zatímco můj starý Seagate Medalist obsahoval asi deset položek, nový Maxtor DiamondMax 10 jich má hned třicet.
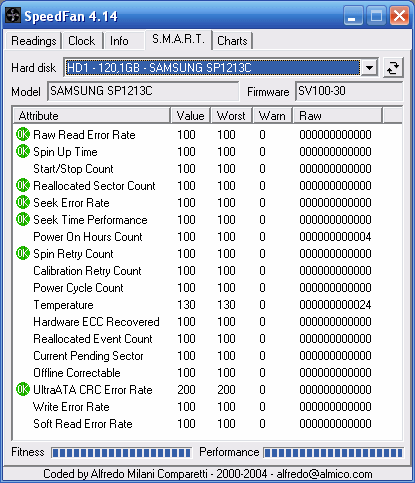
Takto vypadají hodnoty S.M.A.R.T. u nového pevného disku.
Hodnoty S.M.A.R.T. umí zjistit mnoho programů, dle mě jedním z nejlepších v tomto ohledu je SpeedFan - a to hlavně proto, že má dobrou podporu ze strany výrobců čipsetů, takže si poradí i s některými specifickými řadiči jako je Serial ATA na VIA VT8237 či jiné (...a patrně ho už tak nebo tak máte nainstalovaný). Bohužel bez podpory řadiče program není schopen přistupovat k disku, tj. ani přečíst si z něj hodnoty S.M.A.R.T. V tomto má přeci jenom výhodu klasické IDE rozhraní oproti Serial ATA, neb IDE funguje na všech základních deskách stejně (např. má vždy IRQ14 pro první kanál a IRQ15 pro druhý kanál), čili je vždy kompatibilní s programy - avšak pozor, toto neplatí, pokud je disk připojen přes přídavný řadič, tam je situace stejná jako u Serial ATA.
S.M.A.R.T. ukazuje mnoho údajů, z nichž u některých si nikdy nebudete jistí, co přesně znamenají. Navíc u každého typu se mohou různé ukazatele chovat různým způsobem. Je proto dobré sledovat ihned po koupi, co se mění. Nový disk má hodnoty vynulovány a je zcela běžné, že při prvních dnech používání se tyto hodně mění - ustalují se. Pokud to nejsou klíčové položky (viz. níže), není se čeho obávat.
Čtyři položky značí stav:
Value - aktuální výsledná hodnota (obecně čím menší hodnota, tím hůře)
Worst - nejhorší výsledná hodnota
Warn - výsledná hodnota, při jejímž dosažení či překročení (překročení znamená, že Value je menší než Warn) již není doporučeno disk používat, protože některé jeho parametry dosáhly kritických mezí spolehlivosti
Raw - aktuální či kumulovaná hodnota sledovaného parametru (obecně čím více, tím hůře)
Rozdíl mezi Value a Raw lze snadno demonstrovat například na počtu provozních hodin. Pokud bude Value ukazovat 90, znamená to, že 10 procent z předpokládané životnosti disku v hodinách bylo již vypotřebováno. Raw v takovém případě bude ukazovat počet uběhnutých hodin v hexa formátu. Pro uživatele je nejdůležitější parametrem právě Raw, na němž je možné vysledovat přicházející problémy.
Význam položek
Co je důležité sledovat? Některé položky jsou více méně informativní, jiné klíčové.
| Raw Read Error Rate | Počet chybných čtení dat z plotny. Disk běžně má problémy se čtením dat, což koriguje pomocí ECC a opakovaného čtení. U některých disků (typicky Seagate) se počítá celkový počet chybných čtení (tedy hodnota rychle roste), u jiných disků pouze počet čtení, které nebylo možné opravit (v takovém případě by měla být Raw hodnota rovna nule, v opačném případě rychle zálohujte). |
| Spin Up Time | Čas potřebný k roztočení ploten. S časem se zhoršuje, avšak poměrně pomalu. Náhlá změna značí poškození motorku otáčejícího plotny. |
| Start/Stop Count | Počet startů plotny, hodnota v Raw udává kumulovaný součet. Motorek by měl vydržet cca. 50 tisíc startů. |
| Reallocated Sector Count | Počet přemapovaných sektorů z původní do záložní oblasti disku. Ideální hodnota je nula. Při rychlých nárůstech či vysokých hodnotách zálohujte. |
| Seek Error Rate | Počet chybných seeků (přemísťování hlavy nad stopu plotny). U většiny disků by mělo být rovno nule, jinak potřeba zálohovat. |
| Seek Time Performance | Rychlost seekování. Neobvyklé změny hodnoty značí problémy se čtecí / zapisovací hlavou. |
| Power On Hours Count | Počet odpracovaných provozních hodin. V Raw je počet uběhnutých časových jednotek, což u některých disků bývá počet hodin (v hex), u jiných to ale mohou být např. pětiminutové intervaly. |
| Spin Retry Count | Počet opakovaných pokusů o roztočení ploten. Pokud není rovno nule, zálohujte. |
| Calibration Retry Count | Počet opakovaných pokusů o rekalibraci. Mělo by být rovno nule. |
| Power Cycle Count | Obdoba Start/Stop Count. U některých disků stejná hodnota, u jiných rozdílná v závislosti na různých faktorech (např. odlišováno vypnutí a Suspend-to-RAM). |
| Temperature | Teplota disku (ve Value). Raw má někdy stejnou hodnotu jako Value, jindy neidentifikovatelné číslo. Worst udává nejvyšší kdy dosaženou teplotu. |
| Hardware ECC Recovered | Počet opravených chybných čtení (viz. Raw Read Error Rate). Obvykle rychle roste, což ale není na škodu. |
| Reallocated Event Count | Počet sektorů k přealokování (1 sektor = 512 byte). Jakákoliv hodnota vyšší než nula značí problémy. |
| Current Pending Sector | Počet sektorů, jejichž stav je podezřelý. Po spuštění diagnostických utilit bývá obvykle použití sektoru zakázáno a tento nahrazen jiným sektorem ze záložní oblasti. Current Pending Sector se proto vynuluje a o stejnou hodnotu vzroste Reallocated Sector Count. |
| Offline Correctable | Počet problémových sektorů, které je možné nahradit ze záložní oblasti. Pokud hodnota není stejná jako Reallocated Event Count, značí to závažné problémy disku, které nelze ošetřit ani diagnostickými utilitami. V takovém případě je třeba disk reklamovat. |
| UltraATA CRC Error Rate | Počet chyb v komunikaci s řadičem. V Raw je kumulováno počet těchto chyb. Pokud není nula, značí to problémy s kabelem (poškození vodičů, přílišné rušení atp.) či problémy řadiče samotného - například při přetaktování. |
| Soft Read Error Rate | ???. Hodnota rozdílná od nuly značí problémy. |
V případě problémů se sektory (Reallocated Event Count a Current Pending Sector není rovno nule) je možné spuštěním diagnostických utilit výrobce tyto přealokovat do záložní oblasti. Obvykle se tomuto postupu říká Low Level Format, i když to není zcela přesné, protože zde nedochází k nahrazování značek. Co program provede, je, že prozkoumá čitelnost všech sektorů a problémové přealokuje. Mimo to program provede tzv. Zero Write (či Zero Fill), což, jak název napovídá, není nic jiného než zapsání nul na celý povrch disku. Tím se magnetizovatelná látka pročistí do výchozí podoby a připraví se pro nové zmagnetizování. Přirozeně při tom přijdete o všechna data na disku uložená. Osobně doporučuji zero write preventivně spouštět jednou za rok, pokud k tomu máte možnosti (tedy především čas a místo na zálohu dat - ideální je to například pro RAID 1). Zabráníte tím náhodné změně dat sektoru v důsledku nepoužívání.
Jedním z nejznámějších diagnostických programů je Drive Fitness Test
Odkazy na diagnostické utility:
IBM / Hitachi - Drive Fitness Test
Seagate - SeaTools
Maxtor - PowerMax
Western Digital - Data Lifeguard
Samsung - H-Util
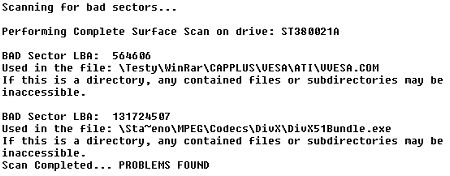
SeaTools našly na disku problémové sektory ve dvou souborech. Disk tyto sektory sice dokázal po asi minutě snahy přečíst, elektronika je však preventivně přealokovala.
Co dělat, když už disk nefunguje?
Když už se disk porouchal, je třeba si ujasnit, co se mu stalo (viz. část "typy poškození"). V případě poškození elektroniky stačí tuto vyměnit za elektroniku ze zcela stejného disku (stejná modelová řada, stejná kapacita a pokud možno i stejný firmware), nastartovat, zazálohovat data, namontovat zpět původní elektroniku a disk odnést na reklamaci. Horší je situace, kdy se disk porouchal mechanicky. V případě vzniku prvního chybného sektoru je nutné ihned zálohovat, protože se může snadno stát, že chyby budou přibývat rapidním tempem a během pár hodin provozu již data zachránit nepůjdou. Někdy se ale může ukázat, že disk po vytvoření asi deseti až dvaceti chybných sektorů (tzv. BBček - Bad Blocks) již pracuje zcela v pořádku několik let - v případě reklamace disku se tak vystavujete potenciálně většímu riziku ztráty dat při chybě nového disku. Osobně takto mám dva disky Seagate a musím přiznat, že jim i přes nějaké ty BBčka věřím.
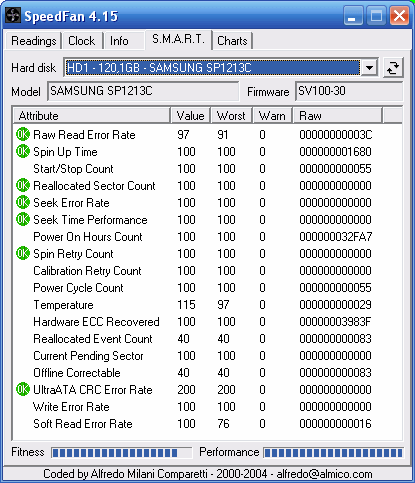
Takto dopadl disk zmíněný výše po třech měsících provozu - Týden poté, co Raw Read Error Rate přestal být nulový, se na disku objevily chybné sektory, které začaly rychle přibývat. Na snímku je 131 (83h) sektorů k přemapování.
V případě katastrofálního selhání (např. poškození čtecí / zapisovací hlavy, porucha motoru točícího plotnami) je nutné disk odnést do specializované firmy provádějící záchranu dat. Taková záchrana ovšem vyjde dost draho, v řádu tisíců až desetitisíců Kč. Pořízení RAIDu 1 (zrcadlení dvou disků) je v konečném důsledku mnohem levnější. Mimo to při fatálním selhání téměř nikdy nelze obnovit z disku všechna data.
Z uvedeného je vidět, že jakožto uživatel můžete zachraňovat data pouze při vzniku chybných sektorů a případně i při poruše elektroniky (pokud ovšem máte náhradní). Plyne z toho jediné - zálohovat se vyplatí, vždyť data jsou na počítači to nejcennější.
Co udělá prodejce / výrobce při reklamaci (RMA)?

Maxtor tvrdí, že počet ročně vrácených disků je méně než 1 procento. Je to ale pravda?
V době tvrdých cenových tlaků a klesajícího zájmu o výnosné velké kapacity se výrobci musí snažit minimalizovat množství vrácených pevných disků. Řešení v takovém případě je vcelku jednoduché - výrobce disk opravuje jeho přeformátováním. V továrně při výrobě disk formátují (vytváří na něm navigační značky), přičemž vždy narazí na nějaké chyby. Tyto chyby jsou přealokovány do jiných oblastí, jinými slovy místo s chybou je nahrazeno volným místem v jiné části disku (vyrobit celou plotnu bez jediné chyby je prakticky nemožné - stejně se dnes postupuje i při výrobě např. procesorů, které také obsahují záložní bloky). Elektronika disku je na toto nastavena, takže pro uživatele to nemá žádný negativní dopad.
Při opravě chybného disku po vzniku chybných sektorů pak stačí tento znovu low level naformátovat. Výrobce pak nemusí disk vyhodit do koše a ušetří. Jenže pokud už plotna selhávala z důvodu nějakého skrytého defektu, může se snadno stát, že disk z reklamace bude mít větší riziko havárie než průměrný nový disk. Toto se hojně stávalo u disků IBM Deskstar 75GXP, kde si uživatelé velmi stěžovali, že disky přijaté z reklamace selhávají stejně rychle nebo dokonce rychleji než jejich původní kus. Proto pozor, obecně se spíše nevyplatí reklamovat disk, na kterém vzniklo několik málo chybných sektorů, ale jinak již běží bez problémů. Samozřejmě že při rapidně narůstajícím množství BBček či při chybném čtení je nutné se disku co nejrychleji zbavit.
Které disky jsou spolehlivé?
V zásadě platí, že všechny značky se porouchávají. Neexistuje jediná značka, která by byla absolutně spolehlivá. A to bohužel platí i o drahých SCSI discích pro servery. Emocionální diskuze na různých fórech pouze potvrzují, že jistotu o data nemůžete mít nikdy. Problémem při hodnocení spolehlivosti je především to, že příslušná statistická data je možné získat až po dlouhé době, tedy v okamžiku, kdy se disk téměř neprodává.

Který selže příště?
Přesto existuje databáze zkušeností s pevnými disky. Najdete jí na serveru StorageReview po zaregistrování se a vyplnění vlastních zkušeností (link -
http://www.storagereview.com/map/lm.cgi/survey_login Závěr - zásady pro zlepšení spolehlivosti disku
). Údaje v této databázi se netýkají jen porouchaných, ale také plně funkčních pevných disků, takže můžete snadno získat představu, jak jsou které generace na tom. Musím říct, že údaje z této databáze vcelku odpovídají "drbům", které se ke mně dostanou z jiných zdrojů - například od kamarádů, kteří mají kamarády v nějakém tom větším obchodě (statistiky o poruchovosti jsou samozřejmě velmi pečlivě střeženy).
Na závěr shrnutí, co je možné udělat, aby měl disk co nejoptimálnější podmínky, tj. co nejdelší životnost:
- chlaďte disk na teplotu pod 40 stupňů Celsia
- pořiďte si online záložní zdroj napájení (UPS vytvářející střídavý proud z baterií)
- disk nepřenášejte a vyhněte se náhlým změnám provozního prostředí
- striktně dodržujte frekvenci řadiče disků (tj. neměňte frekvenci south bridge čipsetu přetaktováním)
- používejte co nejkratší kabely pokud možno se stíněním, kabely ve skříni veďte co nejdál od napájecích kabelů, disk nevystavujte silným zdrojům elektromagnetického záření (umístěte ho co nejdál od zdroje)
- pořiďte si kvalitní ATX12V zdroj odpovídající energetické náročnosti počítače
Pokud k tomu budete průběžně sledovat hodnoty ze S.M.A.R.T., riziko ztráty dat tím výrazně zredukujete. Ještě větší jistotu lze získat použítím RAID1, o tom si ale povíme až příště.


















