AMD na svých stránkách zveřejnilo srovnání výkonu svého AI akcelerátoru Instinct MI300X vůči konkurenčnímu řešení od Nvidie. Výkonem jde o podobné výsledky a AMD má i jednu významnou výhodu navíc.
Společnost AMD ukázala na svých stránkách srovnání akcelerátorů Instinct MI300X s konkurencí, konkrétně s akcelerátory Nvidia DGX H100. Nejde ale o nějaké komplexní porovnání, týká se totiž jednoho LLM, a to konkrétně inference v benchmarku MLPerf v1.4, ve kterém byl měřen výkon pro model LLaMa 2 70B. Testovaly se tři sestavy s 8 kartami, a to AMD Instinct MI300 s procesory AMD Genoa, totéž s novějšími procesory AMD Turin a pak Nvidia DGX 100 s procesory Intel Xeon. V případě serverového testu, který testuje real-time nasazení se striktními limity na latence, bylo řešení s MI300X nejrychlejší, ale Nvidia byla jen v těsném závěsu. Zajímavé je, že řešení s MI300X a staršími EPYCy bylo ještě pomalejší, což ukazuje závislost výkon na procesoru, což celé srovnání akcelerátorů docela shazuje.
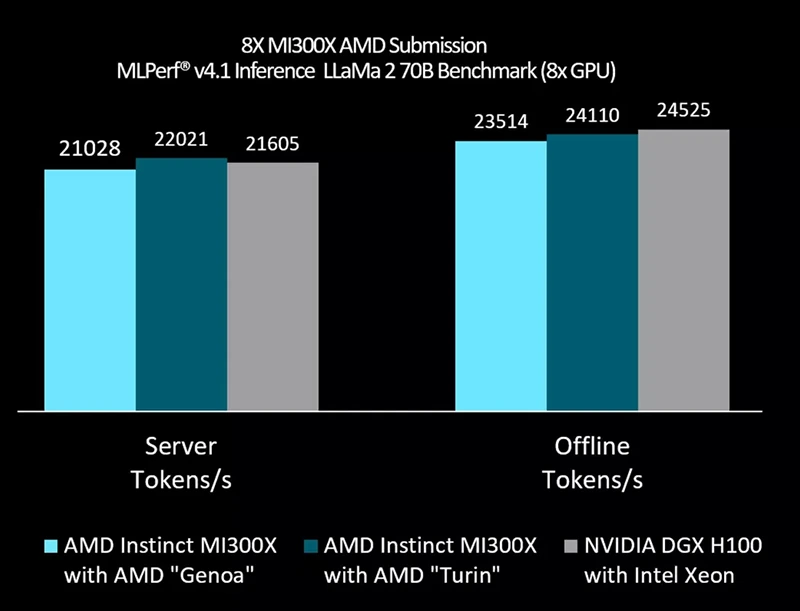
Jak můžeme vědět, že za nižší výsledek Nvidie může výkon akcelerátorů Nvidia a nemůže za to použitý Xeon? Jak by vypadaly výsledky, kdyby byly i Nvidie párovány se stejnými procesory od AMD? Bylo by to lepší nebo horší? To se už nedozvíme.
Současně jde vidět, že v režimu offline, kdy jde o dávkové zpracování obrovského množství tokenů najednou, je už řešení Nvidie nejvýkonnější. V obou případech byly ale rozdíly mezi servery méně než 2 %, což ukazuje schopnost AMD konkurovat velmi oblíbenému řešení od Nvidie.

Dále AMD ukázalo, že výkon se velmi dobře škáluje s počtem použitých karet. Když bylo použito 8 karet místo jedné, naměřený výkon byl 7,7 až 8,3krát vyšší než s jednou kartou. To je dobrý výsledek, neboť algoritmy se často potýkají s tím, že čím více výpočetních systémů přidáte, tím větší je režie jejich komunikace ve srovnání s užitečnými výpočty a výkon přestane růst lineárně s nárůstem počtu výpočetních jednotek. Zde je ale počet karet poměrně nízký na to, aby se takový problém výrazněji projevoval.

Zatímco výkonem tak AMD ukázalo s Nvidií paritu, ale nikoli vítězství, jednoznačně má jednu významnou výhodu. MI300X má 192 GB HBM3 paměti, což znamená, že se na jedinou kartu vejde celý model LLaMa 2 70B. Pokud jde o obří 405miliardový LLaMa 3.1 405B (v FP16 tento model vyžaduje více než 1000 GB), tak ten se s přehledem vejde do clusteru 8 karet Instinct MI300X (ty mají 8×192 GB, tedy 1536 GB), zatímco to už nestačí pro 8 karet Nvidia H100, které s 80GB pamětí na kartu dosáhnou celkem jen 640 GB.