
Technologie: grafické karty jakožto koprocesory...
Technologie: grafické karty jako koprocesory a výkonnostní srovnání CUDA s V8
Poznámka: tento článek vychází z následujících dvou článků napsaných v anglickém jazyce na zahraničním serveru BeHardware, jejichž původním autorem je Damien Triolet.
http://www.behardware.com/articles/659-1/nvidia-cuda-preview.html
http://www.behardware.com/articles/678-1/nvidia-cuda-practical-uses.html
Všude se hovoří o převratné technologii nVidia CUDA, jejím praktickém nasazení a o tom, že vytlačí klasické procesory. Není tedy od věci se na moderní grafické čipy, na kterých je tato technologie provozována, stejně jako na samotnou CUDA podívat a provést výkonnostní srovnání s klasickými procesory v paralelních výpočtech v praxi. Nesmím se samozřejmě nezmínit i o dalších masivně paralelizovaných produktech jiných společností.
Srovnání GPU a CPU
Ačkoliv CPU a GPU byly na začátku v podstatě jedno a to samé (první GPU byl vlastně pomalejší koprocesor zaměřený na grafiku), postupem času se konstrukčně i výkonově značně rozcházely.

GPU je sice mnohem výkonnější, ale to se týká jen většího množství paralelně zpracovávaných úloh. Grafické karty jsou totiž konstruovány pro co největší množství současně zpracovaných vláken, čili pro zpracování co nejvíce dat v co nejmenším čase. CPU je naproti tomu děláno na maximální výkon, nehledě na typ a množství zpracovávaných úloh; ačkoliv v poslední době jsou i zde snahy o co největší paralelizaci i u běžných procesorů pro domácí použití, tato paralelizace ale zatím ve většině případů není vůbec, či jen málo využita.

V praxi to tedy vypadá tak, že dvouprocesorová platforma má osm jader, které pracují na vyšší frekvenci, tím pádem potřebují větší cache. Více jader umožňuje zpracovat více programových vláken, ale v případě programů, které využívají pouze jedno jádro, vše zachraňuje vysoká frekvence, neboť za stejnou jednotku času se zpracuje více dat sériově. Naproti tomu ve dvou grafických kartách s čipy G80 je celkem 128 „jader“ každé má podstatně nižší frekvenci a tedy i potřebnou velikost cache. To je skvělé pro aplikaci, která je umí využít, anebo pro běh mnoha aplikací současně. Pokud ale nemáme ani jedno, výkon je degradovaný na to, co spočítá jediné jádro a to je díky horším parametrům oproti CPU mnohem pomalejší.
Jak vypadá GeForce 8800: bližší pohled
Jádro a výpočetní jednotky
Jádro G80 sestává z osmi samostatných multiprocesorů. Každý multiprocesor obsahuje dvakrát osm SP (Scalar Processor, skalární procesor), pracujících podobně jako jednotky SIMD (Single Instruction, Multiple Data, jedna instrukce, více dat), určené hlavně pro sčítání a násobení, a dvakrát dvě jednotky SFU (Super Function Unit) pro speciální operace (sinus, cosinus, logaritmy atd.).

Fyzicky je vlastně multiprocesorů osm (se šestnácti SP), ale právě díky integraci 2 x 8 SP a 2 x 2 SFU to vypadá, že jich je šestnáct (tedy s osmi SP; bližší detaily implementace nVidia tají, ale tím se stejně nemusíme zatěžovat). Výpočetní jednotky SP jsou taktovány na dvojnásobek základní frekvence (1,5 GHz u GeForce 8800 Ultra). Multiprocesor totiž jednotky používá pro vykonání instrukce na skupině 32 částí (každá část je nazvaná thread, tedy vlákno, ale neplést s programovými vlákny u CPU), skupiny všech 32 vláken se pak jmenují warps (dále budu používat tento výraz počeštěný).

Na takové skupině warpů se pak spouští kernel. Jednotlivá vlákna ve skupině spolu komunikují přes sdílenou paměť. Dvojnásobná frekvence je nutná kvůli vykonání úlohy na celém warpu, na což jsou třeba dva cykly (fyzicky je zde 16 SP), čímž se deficit vyrovná. Tato metoda implementace byla zvolena z důvodu jednoduššího použití jedné instrukce za dva cykly, oproti jedné instrukci každý cyklus. U SFU je situace podobná, pouze jsou čtyřikrát pomalejší, ale díky menší preciznosti provádění instrukcí potřebují pouze osm cyklů pro celý jeden warp, místo šestnácti. SFU také provádí celočíselné operace, ale opět díky nižší preciznosti (24 místo 32 bitů) vše trvá pouze dva cykly. Když to tedy shrneme, dohromady je možné zpracovat 512 vláken za dva cykly, tedy 256 operací za jeden cyklus.
GeForce 8800 nejsou podobně jako jiné grafické karty plně v souladu se standardy IEEE – nepodporují denormalizovaná čísla (nutné například pro databáze) a v některých operacích jsou méně přesné (FP32); FP64 ale možná přijde v příští verzi. NVIDIA vše pěkně shrnula do deseti bodů:

Paměti
Procesory na GeForce 8800 jsou schopny zapisovat kamkoliv do pamětí karty a také odkudkoliv číst (gathering a scattering). Bohužel nejsou paměti kešovány a tak latence čtení/zápisu kolísají mezi 200 a 300 procesorovými cykly. Latence (pokud nezávisí na čtení) mohou ale být maskovány řadou matematických instrukcí.

Pokusem jak eliminovat alespoň částečně latence pamětí je, aby procesory nemusely tak často do pamětí karty zapisovat a číst z nich. Proto je každý multiprocesor vybaven ještě 16 KB tzv. sdílené paměti, sloužící pro vzájemnou komunikaci. Tato sdílená paměť je ovšem pouze pro části konkrétního bloku, tím pádem vlastně každých osm procesorů má k dispozici 8 KB. Čím více threadů přistupuje do této paměti, tím méně připadá na každý jeden, což se řeší přistoupením jednoho procesoru, zatímco druhý počítá (nebo nedělá vůbec nic).
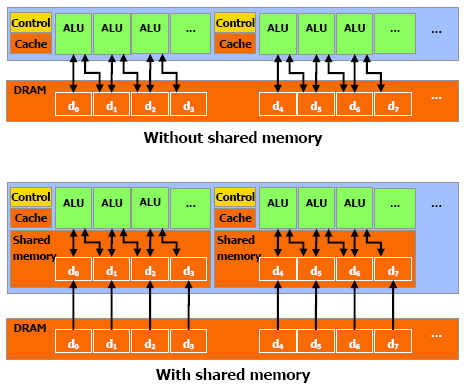
Pro využívání sdílené paměti jsou tedy určitá pravidla. Paměť je dělená do šestnácti banků a vede k ní šestnáct 32bitových sběrnic. Proto pokud máme jeden warp sestávající ze 32 vláken, je tu 32 požadavků na vstup do paměti, ale vykonáno může být pouze šestnáct. V prvním cyklu tedy přistupuje do paměti jen šestnáct vláken a v druhém cyklu zbylých šestnáct. Každé vlákno přitom může přistupovat v případě potřeby do stejného banku, ale ne současně, na to je potřeba více cyklů.
GPU má dále cache pro texturovací jednotky (8 KB na multiprocesor), ze které může být velmi efektivně čteno, pokud jsou požadavky na čtení dobře seřazeny, ale nelze do ní psát. Pak jsou zde i registry, přičemž čím více threadů, tím lepší mohou být v některých případech latence, ale tím méně je registrů přístupných. Nakonec má ještě GeForce 8800 64 KB zvláštní paměti pro konstanty, přičemž je tato paměť kešovaná a připadá opět 8 KB na multiprocesor.
Grafická karta jako koprocesor
První myšlenky: ATi
První myšlenky na „návrat“ ke kořenům, tedy využití grafických karet jako koprocesorů pro jiné než grafické výpočty, dostala ATi někdy kolem uvedení Radeonu X1800, tedy v listopadu 2005. Jednalo se o nízkoúrovňový přístup ke grafické kartě bez využití OpenGL či Direct3D, nazvaný DPVM (Data Parallel Virtual Machine), brzy na to přejmenovaný na CTM (Close To Machine či Close to Metal). První výsledky byly oznámeny v srpnu 2006, zejména ve spojitosti s akcelerací výpočtů projektu Folding@Home, které ale stále využívaly Direct3D. V listopadu téhož roku přišly první Stream Procesory, což vlastně byly upravené X1900 využívající CTM, po těch se ale fakticky slehla zem.

Pro zvětšení klikněte
S R600 přišla nová vlna nadšení a předvedení PC s výkonem 1 Tflops. AMD dodělalo podporu AMD Runtime, poté přišla knihovna matematických funkcí a nakonec i podpora jazyka C. Společnost momentálně kritizuje nVidii a její technologii CUDA kvůli přílišné složitosti, ale pravdou je, že nVidia nyní má funkční, výkonné a jednoduché systémy na trhu s neustálými probíhajícími optimalizacemi, zatímco AMD stále ještě optimalizuje nízkoúrovňový systém a zatím na trhu nemá nic.
Ale přece jen AMD něčeho dosáhlo – Radeony HD série 2000 mají na rozdíl od GeForce 8800 vylepšenou správu pamětí, ty totiž ještě obsahují vyrovnávací paměť před samotnými grafickými paměťmi, sloužící zejména pro zápis. Nová jádra RV670 dokonce již počítají s dvojitou precizností.

Pro zvětšení klikněte
Také používá speciální nástroj pro přenosy přes PCIe paralelně spolu se zbytkem karty. Po stránce „železa“ je na tom tedy AMD opravdu dobře, ale ještě by to chtělo železo oživit. Zcela jistě se něčeho dočkáme nejpozději příští rok s novými grafickými kartami, ale to už může mít nVidia poměrně velkou důvěru i v oblastech jiných, než využívajících superpočítače, a z toho plynoucí síť zákazníků.
nVidia CUDA
CUDA (Compute Unified Device Architecture) je na rozdíl od CTM u AMD vysokoúrovňovým systémem, což znamená, že sice nedosahuje maximálního možného výkonu, ale je značně jednodušší (neboť jak je známo, programátoři jsou líní tvorové).

Jak je vidět z obrázku, aplikace, která je přímo ručně napsaná ve strojovém kódu a optimalizovaná pro GPU, může k GPU přistoupit přes ovladač rovnou (AMD zde nabízí psaní v HLSL, což je o dost jednodušší a výkon je přitom stejný).

V opačném případě, kdy je kupříkladu napsaná v jazyku C, musí využít CUDA Runtime pro překompilování do podoby vhodné k co nejlepšímu využití multiprocesorů, kde ale samozřejmě nastane propad výkonu (je to jako u CPU – čím vyšší a „komfortnější“ jazyk, tím náročnější na zdroje a méně optimalizovaný je). Případně ještě může použít knihovny matematických funkcí.
Nyní není od věci trochu nahlédnout do fungování API Runtime. Obsahuje několik rozšíření C. Kromě standardní knihovny pro C (spuštěny mohou být na CPU i GPU) jsou to komponenty potřebné pro správu GPU a další pro samotný překlad a spuštění na GPU. Pochopitelně je nutné určit, na čem vlastně má být příkaz proveden. Kernel či funkce vyžádaná CPU a zpracovaná v GPU je postoupena jako __GLOBAL__, funkce použitá v kernelu __DEVICE__ a standardní funkce __HOST__. Syntaxe je od klasické
funkce(parametry);
mírně odlišná:
funkce<<< bloky, vlákna, paměť >>>(parametry)
Kde bloky reprezentují počet bloků vláken, vlákna počet vláken v bloku a paměť volitelnou velikost alokované části sdílené paměti. Celkový počet vláken, podílející se pak na zpracování úlohy, je násobek bloky x vlákna.
Balík integrovaných proměnných umožňuje identifikovat vlákno uprostřed několika bloků. Další funkce jsou určeny pro správu GPU, alokování paměťových oblastí a obnovování informací (např. o počtu GPU v systému, o jejich využití, o přidělování úloh apod.). Pak je tu ještě skupina matematických funkcí umožňující synchronizaci vláken - (__synchthreads() ). To způsobí, že se pozastaví vykonávání kernelu, dokud všechna vlákna nedokončí synchronizaci za účelem předejití problémů se zápisem/čtení (aby nedošlo ke čtení dat dříve, než byla správná data do paměti zapsána).

Ke všemu stačí dobrá znalost jazyka C, neboť z něj vše vychází. Pro co nejlepší využití GPU je pak důležité úlohy řadit do gridů ideálně tak, aby právě bylo zaručeno co nejvyšší využití všech vláken.
CUDA také má spoustu funkcí pro zajištění součinnosti 3D API přes buffer pro objekty v OpenGL a vertexové buffery v Direct3D. Je tak například možné spočítat s CUDA fyziku a použít výsledky při 3D renderování.
Co se týče praktického využití, verze 0,8 beta měla několik omezení. Prvně šlo o synchronní verzi, čili procesor nemohl počítat zároveň s kartou. Když tedy procesor poslal práci, „zatuhl“ až do doby, než se výsledky vrátily zpět. Bylo tak potřeba na každou kartu jedno procesorové jádro. Verze 0.9 beta a zejména 1.0 již vyřešila zatuhnutí procesoru po odeslání práce (nyní již může sám na něčem pracovat), nicméně je stále třeba mít jedno procesorové vlákno na každou grafickou kartu. To ovšem není problém, když několik grafických karet nahradí desítky procesorů. Verze 1.0 ještě přinesla další zlepšení práce s pamětí (opět hlavně kvůli případům, kdy vlákno chce číst data, která ještě ani nemusela být přepsána novějšími).
Pokud se blíže podíváme na rychlost výpočtů u GPU při různém uspořádání, je vidět, že rychlost se zvyšuje s počtem „balíků“ dat. V případě jednoho velkého balíku je použit právě jeden multiprocesor, v případě dvou již se využijí dva multiprocesory atd.

Výkon se podstatně zvýší při rozdělení na 16 balíků a optimální je při 32. Pro srovnání je zde graf jak vypadá na jednojádrovém CPU. Tomu je jedno jakým způsobem jsou data uspořádána, počítá je sériově. V případě vícejádrového procesor by se rychlost výpočtu adekvátně zvýšila.
U dvou jader (nehledě na to že vícejádrové procesory ještě nejsou příliš rozšířeny) optimalizace kódu možná ještě nemá velký smysl, neboť je potřeba mnohem delší čas na napsání takového kódu, ale v případě vícejádrových CPU, které nastupují, se to už určitě vyplatí. U grafických karet, které jsou zaměřeny právě na paralelní počítání, je tedy nutné dát si větší práci s kódem, ale o to více času se pak ušetří při samotném zpracování.

Délka výpočetního času při 32 balících, ovšem se stoupajícím počtem operací, stoupá u CPU téměř lineárně, u GPU ale spíše hyperbolicky. Samotná organizace si zřejmě vyžádá dost výpočetní síly, při velkém počtu operací je však rozdíl takřka absorbován.
[BREAK=Další konkurence, využití v praxi, testy a závěr]
Další konkurence – IBM , Sun a Intel
Kromě AMD a nVidie pracuje na masivně paralelizovaných systémech i IBM se svým procesorem Cell. Ten má pouze osm jader a menší propustnost pamětí, ale nabízí vyšší frekvenci a zejména větší cache pro jednotlivá jádra (256 KB). Také Sun se jistě znovu stane na tomto trhu významným hráčem, se svým čipem UltraSPARC 2.
Pro zvětšení klikněte
Konečně nesmíme zapomenout na projekt Intel Larabee, což má být procesor zřejmě s integrovaným grafickým jádrem pro co nejvyšší paralelní výkon; Intel zmínil 16 – 24 jader s 512bitovými SSE jednotkami (tedy šestnáct 32bitových nebo osm 64bitových vláken na každé jádro), každé jádro má mít 32 KB L1 a 256 KB L2 cache.
Využití v praxi
Čísla vypadají pěkně, ale kde to všechno využít ? Rozhodně se takových systémů v blízké době nedočkáme v domácnostech, firmách atd., jednoduše v místech, kde již dvoujádrové „stolní“ procesory nemají využití (větší množství programů a her využívající je v praxi nás potká nejdříve příští rok), nebo kde plně postačují klasické servery. Je tedy jasné, že takové systémy se hodí pouze pro profesionální využití nejvyšší úrovně.
Dosud se právě tyto systémy stavěly pouhým propojení mnoha a mnoha serverových procesorů, IBM začal již dříve kombinovat výhody klasických procesorů a maximálně paralelizovaných čipů v některých systémech BlueGene. S použitím grafických karet by však dosáhl stejného výkonu na mnohem menším prostoru a s nižší cenou. Bohužel prozatím nejsou žádné plány na zbudování takového superpočítače, neboť technologie je to nová a neprověřená. Paměti kupříkladu nepodporují ECC, nVidia také nemá žádné údaje z provozu (počty chyb, spolehlivost systémů, trvanlivost apod.), neboť takové informace se obvykle jen tak nezveřejňují a navíc často chybí (nikde nic takového neběží).
První využití tedy bude zřejmě hlavně v systémech, kde by využití běžných superpočítačů bylo neúnosně drahé a/nebo by stejně nestačilo. nVidia Tesla tak může převzít práci klasických stanic a zastat úkony, které by trvaly dlouho nebo by vůbec nebyly možné. Na konferenci na konci května nVidia pozvala několik firem, kterých by se to mohlo týkat.

Kupříkladu Acceleware vyvíjí systémy založené na GPU pro zrychlení mnoha výzkumů. Společnost předvedla demo simulace dopadu elektromagnetického záření GSM zařízení na lidský mozek, využití je však i v dalších systémech kolem výzkumu nemocí a podobných (například pro rychlou detekci rakoviny prsu či u simulací chování kardiostimulátoru).
Jednou z takových firem je i Evolved Machine, která chce pochopit fungování lidských neuronů pro pochopení pochodů v mozku. Základní struktury se skládají z tisíců neuronů a pro jeden jediný je třeba 200 tisíc diferenciálních rovnic.

S použitím grafických karet v jediném racku zrychlí současnou práci asi 130x, přičemž systém bude stále moci soupeřit s nejvýkonnějšími superpočítači za setinu jejich ceny.
Uplatnění však mohou karty naleznout i u naftařských společností. Ty se při dobývání ropy a zemního plynu dostávají stále hlouběji a se stále lepší technikou, což s sebou nese o to větší množství dat, které se musí zpracovat. Grafické karty celý proces mohou výrazně zkrátit a dokonce podávat výsledky v reálném čase.

První systémy pro tyto společnosti jsou prý již připraveny a ty na ně jen netrpělivě čekají, jak se osvědčí v praxi.
Praktické testy
Pro praktické testy byly serverem BeHardware za pomoci Johna Stonea, staršího výzkumného programátora v oddělení teoretické a výpočtové biofyziky v Beckmanově institutu pro vědu a technologii na Illioniské univerzitě, provedeny programem VMD (Visual Molecular Dynamics), jehož je Stone hlavním vývojářem. VMD je program na analýzu a následné naanimování a zpracování obrovských organických molekul. Nejtěžší část toho všeho je zjistit fungování chemických procesů v molekulách (výměna iontů ve vodním prostředí atd.), test na srovnání jako dělaný.
Pro test bylo VMD překompilováno nástroji nVidie pro CUDA 1.0 na jedné straně a nástroji Intelu pro SSE na straně druhé. CUDA stále vyžadovala pro každou kartu jedno procesorové jádro, navíc zde bylo omezení spočívající v rozdělování úloh. Karta, která spočítá úlohu dříve, musí čekat na ostatní, proto je třeba spojit dvě stejné. Procesory zase více spoléhali na předkalkulaci.
První sestava byla vybavena procesorem Core 2 Extreme QX6850 se dvěma gigabajty DDR2-800 na desce eVGA s čipovou sadou nForce 680i (kde se vystřídaly karty GeForce 8400 GS – tři GeForce 8800 GTX).


Druhá sestava pak byla zástupcem platformy V8 se dvěma Xeony X5365 (4 jádra totožná s QX6850, frekvence 3 GHz) a čipovou sadou Intel 5000X s duálním FSB; deska byla osazena 4 GB FB-DIMM DDR2-667 (teoretická propustnost 21,3 GB/s pro čtení a polovina pro zápis), zapomenout nesmíme na GeForce 8400 pro obraz.
Výsledky
Jako první byl proveden test délky zpracování úlohy.

Procesory E6850 i QX6850 byly značně pomalejší i než karta 8400 GS, která má pouze dva multiprocesory.

V počtu zpracovaných atomů za sekundu opět jasně vítězí grafické karty. Zatímco u 8800 GTX jsou výsledky vždy o polovinu lepší při přidání další karty, u procesorů tomu tak není. To popisuje další graf.

Z něj je vidět, že při prvním zdvojnásobení počtu jader se výkon také přibližně zdvojnásobí (nárůst 93 %), ale u čtyř jader je nárůst již jen 39 %. Problémem je totiž sběrnice, která je na takové množství dat příliš úzkým hrdlem. To dokazuje i další test s různým počtem pamětí.

Při použití čtyř modulů totiž každý využije jeden paměťový kanál. Ačkoliv tak využití pamětí je pouze 900 MB, s vyšším počtem se zvyšuje výkon z důvodu „lepší dostupnosti“ modulů. Jinak musí všechna procesorová jádra využívat jeden jediný paměťový kanál.
Dále jistě není nezajímavé srovnání spotřeby.

Tři grafické karty GeForce 8800 GTX si již řeknou o více než 700 W, ale nesmíme zapomenout, že spotřeba se vždy s jednou kartou zvýší i o jedno procesorové jádro.
Nakonec se na serveru BeHardware zaměřili na energetickou efektivitu přepočítáním počtu atomů na spotřebovaný watt.

Opět suverénně vítězí grafické karty.
Budoucnost grafických karet jakožto koprocesorů
Podle mnohem vyššího výkonu v paralelních výpočtech a jednoduše i dle nemožnosti mnoho výpočtů zastat klasickými procesory, úloha grafických karet rozhodně stoupne. Jak moc záleží na tom, jestli budou efektivnější i než speciální procesory typu Cell a UltraSPARC. O budoucnosti je však již rozhodnuto. Ať se bude vyvíjet jakýmkoliv způsobem, půjde stále k maximalizaci výkonu v rozumných mezích se spotřebou. Nyní to však vypadá, že budoucnost míří k více jádrům a k integraci grafických jader do procesorů pro maximalizaci jejich výkonu a vedle toho použití externích karet v těch nejvýkonnějších systémech.
Zdroj: níže uvedené články na serveru BeHardware, jejichž autorem je Damien Triolet
http://www.behardware.com/articles/659-1/nvidia-cuda-preview.html
http://www.behardware.com/articles/678-1/nvidia-cuda-practical-uses.html
Poznámka: tento článek vychází z následujících dvou článků napsaných v anglickém jazyce na zahraničním serveru BeHardware, jejichž původním autorem je Damien Triolet.
http://www.behardware.com/articles/659-1/nvidia-cuda-preview.html
http://www.behardware.com/articles/678-1/nvidia-cuda-practical-uses.html
Všude se hovoří o převratné technologii nVidia CUDA, jejím praktickém nasazení a o tom, že vytlačí klasické procesory. Není tedy od věci se na moderní grafické čipy, na kterých je tato technologie provozována, stejně jako na samotnou CUDA podívat a provést výkonnostní srovnání s klasickými procesory v paralelních výpočtech v praxi. Nesmím se samozřejmě nezmínit i o dalších masivně paralelizovaných produktech jiných společností.
Srovnání GPU a CPU
Ačkoliv CPU a GPU byly na začátku v podstatě jedno a to samé (první GPU byl vlastně pomalejší koprocesor zaměřený na grafiku), postupem času se konstrukčně i výkonově značně rozcházely.
GPU je sice mnohem výkonnější, ale to se týká jen většího množství paralelně zpracovávaných úloh. Grafické karty jsou totiž konstruovány pro co největší množství současně zpracovaných vláken, čili pro zpracování co nejvíce dat v co nejmenším čase. CPU je naproti tomu děláno na maximální výkon, nehledě na typ a množství zpracovávaných úloh; ačkoliv v poslední době jsou i zde snahy o co největší paralelizaci i u běžných procesorů pro domácí použití, tato paralelizace ale zatím ve většině případů není vůbec, či jen málo využita.
V praxi to tedy vypadá tak, že dvouprocesorová platforma má osm jader, které pracují na vyšší frekvenci, tím pádem potřebují větší cache. Více jader umožňuje zpracovat více programových vláken, ale v případě programů, které využívají pouze jedno jádro, vše zachraňuje vysoká frekvence, neboť za stejnou jednotku času se zpracuje více dat sériově. Naproti tomu ve dvou grafických kartách s čipy G80 je celkem 128 „jader“ každé má podstatně nižší frekvenci a tedy i potřebnou velikost cache. To je skvělé pro aplikaci, která je umí využít, anebo pro běh mnoha aplikací současně. Pokud ale nemáme ani jedno, výkon je degradovaný na to, co spočítá jediné jádro a to je díky horším parametrům oproti CPU mnohem pomalejší.
Jak vypadá GeForce 8800: bližší pohled
Jádro a výpočetní jednotky
Jádro G80 sestává z osmi samostatných multiprocesorů. Každý multiprocesor obsahuje dvakrát osm SP (Scalar Processor, skalární procesor), pracujících podobně jako jednotky SIMD (Single Instruction, Multiple Data, jedna instrukce, více dat), určené hlavně pro sčítání a násobení, a dvakrát dvě jednotky SFU (Super Function Unit) pro speciální operace (sinus, cosinus, logaritmy atd.).
Fyzicky je vlastně multiprocesorů osm (se šestnácti SP), ale právě díky integraci 2 x 8 SP a 2 x 2 SFU to vypadá, že jich je šestnáct (tedy s osmi SP; bližší detaily implementace nVidia tají, ale tím se stejně nemusíme zatěžovat). Výpočetní jednotky SP jsou taktovány na dvojnásobek základní frekvence (1,5 GHz u GeForce 8800 Ultra). Multiprocesor totiž jednotky používá pro vykonání instrukce na skupině 32 částí (každá část je nazvaná thread, tedy vlákno, ale neplést s programovými vlákny u CPU), skupiny všech 32 vláken se pak jmenují warps (dále budu používat tento výraz počeštěný).
Na takové skupině warpů se pak spouští kernel. Jednotlivá vlákna ve skupině spolu komunikují přes sdílenou paměť. Dvojnásobná frekvence je nutná kvůli vykonání úlohy na celém warpu, na což jsou třeba dva cykly (fyzicky je zde 16 SP), čímž se deficit vyrovná. Tato metoda implementace byla zvolena z důvodu jednoduššího použití jedné instrukce za dva cykly, oproti jedné instrukci každý cyklus. U SFU je situace podobná, pouze jsou čtyřikrát pomalejší, ale díky menší preciznosti provádění instrukcí potřebují pouze osm cyklů pro celý jeden warp, místo šestnácti. SFU také provádí celočíselné operace, ale opět díky nižší preciznosti (24 místo 32 bitů) vše trvá pouze dva cykly. Když to tedy shrneme, dohromady je možné zpracovat 512 vláken za dva cykly, tedy 256 operací za jeden cyklus.
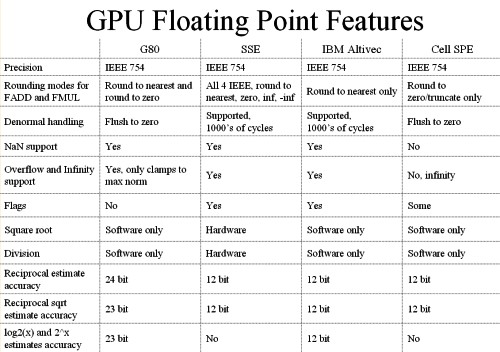
GeForce 8800 nejsou podobně jako jiné grafické karty plně v souladu se standardy IEEE – nepodporují denormalizovaná čísla (nutné například pro databáze) a v některých operacích jsou méně přesné (FP32); FP64 ale možná přijde v příští verzi. NVIDIA vše pěkně shrnula do deseti bodů:
Paměti
Procesory na GeForce 8800 jsou schopny zapisovat kamkoliv do pamětí karty a také odkudkoliv číst (gathering a scattering). Bohužel nejsou paměti kešovány a tak latence čtení/zápisu kolísají mezi 200 a 300 procesorovými cykly. Latence (pokud nezávisí na čtení) mohou ale být maskovány řadou matematických instrukcí.
Pokusem jak eliminovat alespoň částečně latence pamětí je, aby procesory nemusely tak často do pamětí karty zapisovat a číst z nich. Proto je každý multiprocesor vybaven ještě 16 KB tzv. sdílené paměti, sloužící pro vzájemnou komunikaci. Tato sdílená paměť je ovšem pouze pro části konkrétního bloku, tím pádem vlastně každých osm procesorů má k dispozici 8 KB. Čím více threadů přistupuje do této paměti, tím méně připadá na každý jeden, což se řeší přistoupením jednoho procesoru, zatímco druhý počítá (nebo nedělá vůbec nic).
Pro využívání sdílené paměti jsou tedy určitá pravidla. Paměť je dělená do šestnácti banků a vede k ní šestnáct 32bitových sběrnic. Proto pokud máme jeden warp sestávající ze 32 vláken, je tu 32 požadavků na vstup do paměti, ale vykonáno může být pouze šestnáct. V prvním cyklu tedy přistupuje do paměti jen šestnáct vláken a v druhém cyklu zbylých šestnáct. Každé vlákno přitom může přistupovat v případě potřeby do stejného banku, ale ne současně, na to je potřeba více cyklů.
GPU má dále cache pro texturovací jednotky (8 KB na multiprocesor), ze které může být velmi efektivně čteno, pokud jsou požadavky na čtení dobře seřazeny, ale nelze do ní psát. Pak jsou zde i registry, přičemž čím více threadů, tím lepší mohou být v některých případech latence, ale tím méně je registrů přístupných. Nakonec má ještě GeForce 8800 64 KB zvláštní paměti pro konstanty, přičemž je tato paměť kešovaná a připadá opět 8 KB na multiprocesor.
Grafická karta jako koprocesor
První myšlenky: ATi
První myšlenky na „návrat“ ke kořenům, tedy využití grafických karet jako koprocesorů pro jiné než grafické výpočty, dostala ATi někdy kolem uvedení Radeonu X1800, tedy v listopadu 2005. Jednalo se o nízkoúrovňový přístup ke grafické kartě bez využití OpenGL či Direct3D, nazvaný DPVM (Data Parallel Virtual Machine), brzy na to přejmenovaný na CTM (Close To Machine či Close to Metal). První výsledky byly oznámeny v srpnu 2006, zejména ve spojitosti s akcelerací výpočtů projektu Folding@Home, které ale stále využívaly Direct3D. V listopadu téhož roku přišly první Stream Procesory, což vlastně byly upravené X1900 využívající CTM, po těch se ale fakticky slehla zem.
Pro zvětšení klikněte
S R600 přišla nová vlna nadšení a předvedení PC s výkonem 1 Tflops. AMD dodělalo podporu AMD Runtime, poté přišla knihovna matematických funkcí a nakonec i podpora jazyka C. Společnost momentálně kritizuje nVidii a její technologii CUDA kvůli přílišné složitosti, ale pravdou je, že nVidia nyní má funkční, výkonné a jednoduché systémy na trhu s neustálými probíhajícími optimalizacemi, zatímco AMD stále ještě optimalizuje nízkoúrovňový systém a zatím na trhu nemá nic.
Ale přece jen AMD něčeho dosáhlo – Radeony HD série 2000 mají na rozdíl od GeForce 8800 vylepšenou správu pamětí, ty totiž ještě obsahují vyrovnávací paměť před samotnými grafickými paměťmi, sloužící zejména pro zápis. Nová jádra RV670 dokonce již počítají s dvojitou precizností.
Pro zvětšení klikněte
Také používá speciální nástroj pro přenosy přes PCIe paralelně spolu se zbytkem karty. Po stránce „železa“ je na tom tedy AMD opravdu dobře, ale ještě by to chtělo železo oživit. Zcela jistě se něčeho dočkáme nejpozději příští rok s novými grafickými kartami, ale to už může mít nVidia poměrně velkou důvěru i v oblastech jiných, než využívajících superpočítače, a z toho plynoucí síť zákazníků.
nVidia CUDA
CUDA (Compute Unified Device Architecture) je na rozdíl od CTM u AMD vysokoúrovňovým systémem, což znamená, že sice nedosahuje maximálního možného výkonu, ale je značně jednodušší (neboť jak je známo, programátoři jsou líní tvorové).
Jak je vidět z obrázku, aplikace, která je přímo ručně napsaná ve strojovém kódu a optimalizovaná pro GPU, může k GPU přistoupit přes ovladač rovnou (AMD zde nabízí psaní v HLSL, což je o dost jednodušší a výkon je přitom stejný).
V opačném případě, kdy je kupříkladu napsaná v jazyku C, musí využít CUDA Runtime pro překompilování do podoby vhodné k co nejlepšímu využití multiprocesorů, kde ale samozřejmě nastane propad výkonu (je to jako u CPU – čím vyšší a „komfortnější“ jazyk, tím náročnější na zdroje a méně optimalizovaný je). Případně ještě může použít knihovny matematických funkcí.
Nyní není od věci trochu nahlédnout do fungování API Runtime. Obsahuje několik rozšíření C. Kromě standardní knihovny pro C (spuštěny mohou být na CPU i GPU) jsou to komponenty potřebné pro správu GPU a další pro samotný překlad a spuštění na GPU. Pochopitelně je nutné určit, na čem vlastně má být příkaz proveden. Kernel či funkce vyžádaná CPU a zpracovaná v GPU je postoupena jako __GLOBAL__, funkce použitá v kernelu __DEVICE__ a standardní funkce __HOST__. Syntaxe je od klasické
funkce(parametry);
mírně odlišná:
funkce<<< bloky, vlákna, paměť >>>(parametry)
Kde bloky reprezentují počet bloků vláken, vlákna počet vláken v bloku a paměť volitelnou velikost alokované části sdílené paměti. Celkový počet vláken, podílející se pak na zpracování úlohy, je násobek bloky x vlákna.
Balík integrovaných proměnných umožňuje identifikovat vlákno uprostřed několika bloků. Další funkce jsou určeny pro správu GPU, alokování paměťových oblastí a obnovování informací (např. o počtu GPU v systému, o jejich využití, o přidělování úloh apod.). Pak je tu ještě skupina matematických funkcí umožňující synchronizaci vláken - (__synchthreads() ). To způsobí, že se pozastaví vykonávání kernelu, dokud všechna vlákna nedokončí synchronizaci za účelem předejití problémů se zápisem/čtení (aby nedošlo ke čtení dat dříve, než byla správná data do paměti zapsána).
Ke všemu stačí dobrá znalost jazyka C, neboť z něj vše vychází. Pro co nejlepší využití GPU je pak důležité úlohy řadit do gridů ideálně tak, aby právě bylo zaručeno co nejvyšší využití všech vláken.
CUDA také má spoustu funkcí pro zajištění součinnosti 3D API přes buffer pro objekty v OpenGL a vertexové buffery v Direct3D. Je tak například možné spočítat s CUDA fyziku a použít výsledky při 3D renderování.
Co se týče praktického využití, verze 0,8 beta měla několik omezení. Prvně šlo o synchronní verzi, čili procesor nemohl počítat zároveň s kartou. Když tedy procesor poslal práci, „zatuhl“ až do doby, než se výsledky vrátily zpět. Bylo tak potřeba na každou kartu jedno procesorové jádro. Verze 0.9 beta a zejména 1.0 již vyřešila zatuhnutí procesoru po odeslání práce (nyní již může sám na něčem pracovat), nicméně je stále třeba mít jedno procesorové vlákno na každou grafickou kartu. To ovšem není problém, když několik grafických karet nahradí desítky procesorů. Verze 1.0 ještě přinesla další zlepšení práce s pamětí (opět hlavně kvůli případům, kdy vlákno chce číst data, která ještě ani nemusela být přepsána novějšími).
Pokud se blíže podíváme na rychlost výpočtů u GPU při různém uspořádání, je vidět, že rychlost se zvyšuje s počtem „balíků“ dat. V případě jednoho velkého balíku je použit právě jeden multiprocesor, v případě dvou již se využijí dva multiprocesory atd.
Výkon se podstatně zvýší při rozdělení na 16 balíků a optimální je při 32. Pro srovnání je zde graf jak vypadá na jednojádrovém CPU. Tomu je jedno jakým způsobem jsou data uspořádána, počítá je sériově. V případě vícejádrového procesor by se rychlost výpočtu adekvátně zvýšila.
U dvou jader (nehledě na to že vícejádrové procesory ještě nejsou příliš rozšířeny) optimalizace kódu možná ještě nemá velký smysl, neboť je potřeba mnohem delší čas na napsání takového kódu, ale v případě vícejádrových CPU, které nastupují, se to už určitě vyplatí. U grafických karet, které jsou zaměřeny právě na paralelní počítání, je tedy nutné dát si větší práci s kódem, ale o to více času se pak ušetří při samotném zpracování.
Délka výpočetního času při 32 balících, ovšem se stoupajícím počtem operací, stoupá u CPU téměř lineárně, u GPU ale spíše hyperbolicky. Samotná organizace si zřejmě vyžádá dost výpočetní síly, při velkém počtu operací je však rozdíl takřka absorbován.
[BREAK=Další konkurence, využití v praxi, testy a závěr]
Další konkurence – IBM , Sun a Intel
Kromě AMD a nVidie pracuje na masivně paralelizovaných systémech i IBM se svým procesorem Cell. Ten má pouze osm jader a menší propustnost pamětí, ale nabízí vyšší frekvenci a zejména větší cache pro jednotlivá jádra (256 KB). Také Sun se jistě znovu stane na tomto trhu významným hráčem, se svým čipem UltraSPARC 2.
Pro zvětšení klikněte
Konečně nesmíme zapomenout na projekt Intel Larabee, což má být procesor zřejmě s integrovaným grafickým jádrem pro co nejvyšší paralelní výkon; Intel zmínil 16 – 24 jader s 512bitovými SSE jednotkami (tedy šestnáct 32bitových nebo osm 64bitových vláken na každé jádro), každé jádro má mít 32 KB L1 a 256 KB L2 cache.
Využití v praxi
Čísla vypadají pěkně, ale kde to všechno využít ? Rozhodně se takových systémů v blízké době nedočkáme v domácnostech, firmách atd., jednoduše v místech, kde již dvoujádrové „stolní“ procesory nemají využití (větší množství programů a her využívající je v praxi nás potká nejdříve příští rok), nebo kde plně postačují klasické servery. Je tedy jasné, že takové systémy se hodí pouze pro profesionální využití nejvyšší úrovně.
Dosud se právě tyto systémy stavěly pouhým propojení mnoha a mnoha serverových procesorů, IBM začal již dříve kombinovat výhody klasických procesorů a maximálně paralelizovaných čipů v některých systémech BlueGene. S použitím grafických karet by však dosáhl stejného výkonu na mnohem menším prostoru a s nižší cenou. Bohužel prozatím nejsou žádné plány na zbudování takového superpočítače, neboť technologie je to nová a neprověřená. Paměti kupříkladu nepodporují ECC, nVidia také nemá žádné údaje z provozu (počty chyb, spolehlivost systémů, trvanlivost apod.), neboť takové informace se obvykle jen tak nezveřejňují a navíc často chybí (nikde nic takového neběží).
První využití tedy bude zřejmě hlavně v systémech, kde by využití běžných superpočítačů bylo neúnosně drahé a/nebo by stejně nestačilo. nVidia Tesla tak může převzít práci klasických stanic a zastat úkony, které by trvaly dlouho nebo by vůbec nebyly možné. Na konferenci na konci května nVidia pozvala několik firem, kterých by se to mohlo týkat.
Kupříkladu Acceleware vyvíjí systémy založené na GPU pro zrychlení mnoha výzkumů. Společnost předvedla demo simulace dopadu elektromagnetického záření GSM zařízení na lidský mozek, využití je však i v dalších systémech kolem výzkumu nemocí a podobných (například pro rychlou detekci rakoviny prsu či u simulací chování kardiostimulátoru).
Jednou z takových firem je i Evolved Machine, která chce pochopit fungování lidských neuronů pro pochopení pochodů v mozku. Základní struktury se skládají z tisíců neuronů a pro jeden jediný je třeba 200 tisíc diferenciálních rovnic.
S použitím grafických karet v jediném racku zrychlí současnou práci asi 130x, přičemž systém bude stále moci soupeřit s nejvýkonnějšími superpočítači za setinu jejich ceny.
Uplatnění však mohou karty naleznout i u naftařských společností. Ty se při dobývání ropy a zemního plynu dostávají stále hlouběji a se stále lepší technikou, což s sebou nese o to větší množství dat, které se musí zpracovat. Grafické karty celý proces mohou výrazně zkrátit a dokonce podávat výsledky v reálném čase.
První systémy pro tyto společnosti jsou prý již připraveny a ty na ně jen netrpělivě čekají, jak se osvědčí v praxi.
Praktické testy
Pro praktické testy byly serverem BeHardware za pomoci Johna Stonea, staršího výzkumného programátora v oddělení teoretické a výpočtové biofyziky v Beckmanově institutu pro vědu a technologii na Illioniské univerzitě, provedeny programem VMD (Visual Molecular Dynamics), jehož je Stone hlavním vývojářem. VMD je program na analýzu a následné naanimování a zpracování obrovských organických molekul. Nejtěžší část toho všeho je zjistit fungování chemických procesů v molekulách (výměna iontů ve vodním prostředí atd.), test na srovnání jako dělaný.
Pro test bylo VMD překompilováno nástroji nVidie pro CUDA 1.0 na jedné straně a nástroji Intelu pro SSE na straně druhé. CUDA stále vyžadovala pro každou kartu jedno procesorové jádro, navíc zde bylo omezení spočívající v rozdělování úloh. Karta, která spočítá úlohu dříve, musí čekat na ostatní, proto je třeba spojit dvě stejné. Procesory zase více spoléhali na předkalkulaci.
První sestava byla vybavena procesorem Core 2 Extreme QX6850 se dvěma gigabajty DDR2-800 na desce eVGA s čipovou sadou nForce 680i (kde se vystřídaly karty GeForce 8400 GS – tři GeForce 8800 GTX).
Druhá sestava pak byla zástupcem platformy V8 se dvěma Xeony X5365 (4 jádra totožná s QX6850, frekvence 3 GHz) a čipovou sadou Intel 5000X s duálním FSB; deska byla osazena 4 GB FB-DIMM DDR2-667 (teoretická propustnost 21,3 GB/s pro čtení a polovina pro zápis), zapomenout nesmíme na GeForce 8400 pro obraz.
Výsledky
Jako první byl proveden test délky zpracování úlohy.
Procesory E6850 i QX6850 byly značně pomalejší i než karta 8400 GS, která má pouze dva multiprocesory.
V počtu zpracovaných atomů za sekundu opět jasně vítězí grafické karty. Zatímco u 8800 GTX jsou výsledky vždy o polovinu lepší při přidání další karty, u procesorů tomu tak není. To popisuje další graf.
Z něj je vidět, že při prvním zdvojnásobení počtu jader se výkon také přibližně zdvojnásobí (nárůst 93 %), ale u čtyř jader je nárůst již jen 39 %. Problémem je totiž sběrnice, která je na takové množství dat příliš úzkým hrdlem. To dokazuje i další test s různým počtem pamětí.
Při použití čtyř modulů totiž každý využije jeden paměťový kanál. Ačkoliv tak využití pamětí je pouze 900 MB, s vyšším počtem se zvyšuje výkon z důvodu „lepší dostupnosti“ modulů. Jinak musí všechna procesorová jádra využívat jeden jediný paměťový kanál.
Dále jistě není nezajímavé srovnání spotřeby.
Tři grafické karty GeForce 8800 GTX si již řeknou o více než 700 W, ale nesmíme zapomenout, že spotřeba se vždy s jednou kartou zvýší i o jedno procesorové jádro.
Nakonec se na serveru BeHardware zaměřili na energetickou efektivitu přepočítáním počtu atomů na spotřebovaný watt.
Opět suverénně vítězí grafické karty.
Budoucnost grafických karet jakožto koprocesorů
Podle mnohem vyššího výkonu v paralelních výpočtech a jednoduše i dle nemožnosti mnoho výpočtů zastat klasickými procesory, úloha grafických karet rozhodně stoupne. Jak moc záleží na tom, jestli budou efektivnější i než speciální procesory typu Cell a UltraSPARC. O budoucnosti je však již rozhodnuto. Ať se bude vyvíjet jakýmkoliv způsobem, půjde stále k maximalizaci výkonu v rozumných mezích se spotřebou. Nyní to však vypadá, že budoucnost míří k více jádrům a k integraci grafických jader do procesorů pro maximalizaci jejich výkonu a vedle toho použití externích karet v těch nejvýkonnějších systémech.
Zdroj: níže uvedené články na serveru BeHardware, jejichž autorem je Damien Triolet
http://www.behardware.com/articles/659-1/nvidia-cuda-preview.html
http://www.behardware.com/articles/678-1/nvidia-cuda-practical-uses.html
Celkem dobrá kompilace dvou zajímavých zahraničních článků.
Nedokážu si teda moc dobře představit ten překladač C, protože pro použití SSE/MMX už je nutné dost brutální přizpůsobení datových struktur a časově kritické části je nutné napsat v assembleru (nebo překladač co rozpozná, že kód lze paralelizovat existuje?).
Pak tohle podle mého názoru popisuje programovatelnou část GPU jako vertex/pixel shadery. Něco podrobného o fungování jader GPU jsem nenašel (a už pár let nehledal), ale mám za to, že tam budou jednotky např. pro interpolace pevně zadrátované. Strašná výhoda pak bude krom paralelismu i v tom, že většina operací nemusí čekat na výsledek předchozí a v jednom taktu pak půjde zahájit jednu instrukci, ačkoliv třeba není výsledek z 20ti předchozích.Tohle je teda jen domněnka a případně návrh na volné pokračování o architektuře GPU.
Nedokážu si teda moc dobře představit ten překladač C, protože pro použití SSE/MMX už je nutné dost brutální přizpůsobení datových struktur a časově kritické části je nutné napsat v assembleru (nebo překladač co rozpozná, že kód lze paralelizovat existuje?).
Pak tohle podle mého názoru popisuje programovatelnou část GPU jako vertex/pixel shadery. Něco podrobného o fungování jader GPU jsem nenašel (a už pár let nehledal), ale mám za to, že tam budou jednotky např. pro interpolace pevně zadrátované. Strašná výhoda pak bude krom paralelismu i v tom, že většina operací nemusí čekat na výsledek předchozí a v jednom taktu pak půjde zahájit jednu instrukci, ačkoliv třeba není výsledek z 20ti předchozích.Tohle je teda jen domněnka a případně návrh na volné pokračování o architektuře GPU.
[QUOTE=pavel_p;56500]Celkem dobrá kompilace dvou zajímavých zahraničních článků.
Nedokážu si teda moc dobře představit ten překladač C, protože pro použití SSE/MMX už je nutné dost brutální přizpůsobení datových struktur a časově kritické části je nutné napsat v assembleru (nebo překladač co rozpozná, že kód lze paralelizovat existuje?).
Pak tohle podle mého názoru popisuje programovatelnou část GPU jako vertex/pixel shadery. Něco podrobného o fungování jader GPU jsem nenašel (a už pár let nehledal), ale mám za to, že tam budou jednotky např. pro interpolace pevně zadrátované. Strašná výhoda pak bude krom paralelismu i v tom, že většina operací nemusí čekat na výsledek předchozí a v jednom taktu pak půjde zahájit jednu instrukci, ačkoliv třeba není výsledek z 20ti předchozích.Tohle je teda jen domněnka a případně návrh na volné pokračování o architektuře GPU.[/QUOTE]
No, nepracoval jsem s tím takže přesně neřeknu, ale mělo by to právě nějak rozházet úlohu pro optimální využití všech MP. Asi to ale nebude za moc stát, moc úloh pro to zatím není, lepší je to dělat pěkně ručně. Co se týče toho zpracování, např. u Niagary 2 to tak právě je, že jedno jádro počítá, zatímco další čeká na data, tady to musí být stejně, jinak by výkon byl myslím mnohem nižší.
Nedokážu si teda moc dobře představit ten překladač C, protože pro použití SSE/MMX už je nutné dost brutální přizpůsobení datových struktur a časově kritické části je nutné napsat v assembleru (nebo překladač co rozpozná, že kód lze paralelizovat existuje?).
Pak tohle podle mého názoru popisuje programovatelnou část GPU jako vertex/pixel shadery. Něco podrobného o fungování jader GPU jsem nenašel (a už pár let nehledal), ale mám za to, že tam budou jednotky např. pro interpolace pevně zadrátované. Strašná výhoda pak bude krom paralelismu i v tom, že většina operací nemusí čekat na výsledek předchozí a v jednom taktu pak půjde zahájit jednu instrukci, ačkoliv třeba není výsledek z 20ti předchozích.Tohle je teda jen domněnka a případně návrh na volné pokračování o architektuře GPU.[/QUOTE]
No, nepracoval jsem s tím takže přesně neřeknu, ale mělo by to právě nějak rozházet úlohu pro optimální využití všech MP. Asi to ale nebude za moc stát, moc úloh pro to zatím není, lepší je to dělat pěkně ručně. Co se týče toho zpracování, např. u Niagary 2 to tak právě je, že jedno jádro počítá, zatímco další čeká na data, tady to musí být stejně, jinak by výkon byl myslím mnohem nižší.






