
Seznam kapitol
Již za několik měsíců se do obchodů dostaví první procesory založené na nové architektuře Intel Core. Čipy Conroe, Merom a Woodcrest znamenají dramatickou změnu ve vývoji. Dnes zahájíme povídání o tom, jak nové procesory fungují a co zajímavého přinesou.
Protože dekódovací a přeřazovací část umí dodat až 4 microOPs za hodinový cyklus, musela být náležitě předělána také část procesoru, která provádí samotné operace (zpracovává microOPs). Oproti Pentiu M zde došlo k několika důležitým změnám. Ještě před tím, než se pustíme do popisu počtu a uspořádání, řekněme si něco o změnách na úrovni samotných jednotek.
Vsuvka: Jaké jednotky procesor obsahuje?
Jednotky pro celočíselné skalární operace (
ALU - Arithmetic Logic Unit
) - Jedná se o operace pouze s celými čísly (1, 10, 2526 atp.) a to pouze ve skalárním formátu. Jejich výhodou je poměrně vysoká rychlost a nenáročnost na počet microOPs, neboť jsou obvykle jednoduché. Jednotky zpracovávající je pracují, dle generace procesoru a nastaveného operačního režimu, s 8bit, 16bit, 32bit a 64bit registry a jsou řízeny instrukcemi x86, resp. AMD64. Počet dostupných registrů je v 32bit režimu osm, v 64bit režimu šestnáct (hardwarový počet přejmenovaných registrů je samozřejmě úplně jiný). V drtivé většině programů tvoří x86 většinu kódu.
Skalární operace s desetinnou čárkou jsou prováděny v
FPU (Floating Point Unit
) - Tyto jednotky umí pracovat s čísly s desetinnou čárkou (3,14 atp.) a jsou řízeny instrukcemi x87. Operace probíhají na 32bit, 64bit, resp. 80bit registrech, dle nastavené přesnosti. Čím vyšší přesnost, tím obvykle delší doba na zpracování. Největší velikost - 80bit - se obvykle z důvodů pomalosti a problematického zarovnání v paměti (... což degraduje výkon) nepoužívá. Jednotka FPU je také zodpovědná za
vektorovací instrukce MMX
(MultiMedia eXtension)
.
To jsou celočíselné SIMD operace (viz dále) na dvouprvkovém vektoru (číslo1; číslo2) o celkové velikosti 64bit. Od MMX instrukcí se dnes ustupuje, neboť je zcela nahradila sada SSE, která navíc nesdílí s x87 operacemi registry, takže při jejím zpracování nevzniká nechtěná režie z přepínání.
Vektorovací jednotky SSE
(Streaming SIMD Extensions) - Tyto na vektorové zpracování specializované jednotky pracují se 128bit registry a to ve formě SIMD operací. Možná organizace je 4x 32bit nebo 2x 64bit a to jak pro celočíselné operace, tak pro výpočty s čísly s desetinnou čárkou. Protože SSE dosahuje dobrého výkonu, zaznamenává rostoucí význam, především na úkor x87 a MMX operací. Jediné místo, kde je zatím FPU jednotka nenahraditelná, jsou (pomalé) výpočty s 80bit přesností.
Mnoho současných procesorů obsahuje výpočetní jednotky, které kombinují více instrukčních sad. Konkrétně v architektuře Core jsou takto kombinovány FPU jednotky s vektorovacími SSE jednotkami specializovanými na operaci s čísly s desetinnou čárkou. Celočíselné SSE operace pak probíhají v jiných jednotkách.
Jednotky
Load
- Vypočítávají adresu v paměti při operaci čtení.
Jednotky
Store
- Ukládají data z registru do paměti a vypočítávají adresu v paměti při zápisu.
Významné změny v jednotkách
Core oproti starším architekturám Pentia M a NetBurstu přináší některé novinky, co se výpočetních jednotek týče. Zásadní změnou je, že jednotky pro počítání s celými čísly (ALU) jsou nyní plně 64bit. Zatímco procesory Pentium M vůbec podporu 64bit instrukcí neměly a Pentium 4 mělo podporu slepenou ze dvou 32bit jednotek (... což se negativně projevovalo na výkonu, neboť operace s 64bit čísly zaznamenávaly větší prodlevy při zpracování), Core má od základu předělané jednotky. Díky tomu nová architektura poskytuje plnou podporu instrukční sadě AMD64 (jinak také EM64T nebo x86-64). Mimo to tyto jednotky zvládají provádění 64bit operací za jediný hodinový cyklus, tedy podstatně rychleji než je tomu u všech ostatních architektur.
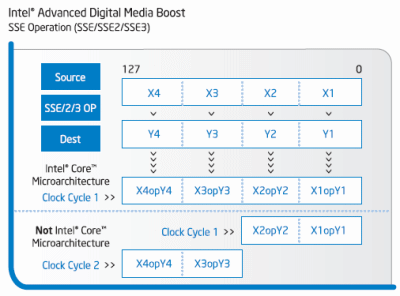
Intel nazývá 128bit SSE jednotky jako Advanced Digital Media Boost
Dalším vylepšením jsou plně 128bit jednotky pro SSE operace. Co toto znamená? SSE znamená Streaming SIMD Extensions. Nejdůležitější slovo je pak SIMD, což je Single Instruction Multiple Data (jedna instrukce, více dat). SIMD zpracování (mezi nějž se počítá i MMX a 3Dnow!) je tzv. vektorové počítání. Ve standardních jednotkách jedna microOP provádí operaci s jedním číslem (tzv. skalární operace). U vektorových počítání provádí jedna microOP operaci s dvou- nebo čtyř-číselným vektorem.
Klasický způsob (Scalar):
první microOP: 5x * 2 = 10
druhá microOP: 5x * 3 = 15
třetí microOP: 5x * 1 = 5
čtvrtá microOP: 5x * 8 = 40
Vektorový způsob (SIMD - Single Instruction Multiple Data):
první microOP: 5x (2; 3; 1; 8) = (10; 15; 5; 40)
V uvedeném příkladě pokaždé dospějeme ke stejným výsledkům a bude zapotřebí stejného počtu dat. Klasický způsob bude ale vyžadovat čtyřikrát více microOPs. Jejich dekódování pak zabere delší dobu (bude trvat více cyklů) a zabere více pozic v Reorder Bufferu. SIMD zpracování je tak jasně efektivnější. Nevýhodou samozřejmě je, že tímto způsobem je možné provádět výpočty pouze v situaci, kdy se operace přiřazené ke všem datům shodují - v příkladu výše se vše násobí 5x, kdyby ale jedno číslo požadovalo násobení 4x, nebude možné SIMD provést.
SIMD operace najdou uplatnění především v multimediálních aplikacích, kde se provádí neustále ty samé výpočty s více daty (zvuk, video, obrázky...).
SSE (a SSE2 a 3) využívá k provádění SIMD operací 128bit registr. Ten může být konfigurován jako 2x 64bit nebo jako 4x 32bit. Možný je výpočet jak celých čísel, tak také čísel s desetinnou čárkou. Protože konstrukce 128bit registru a k tomu připadající jednotky byla poměrně složitá, usnadňovali si návrháři práci tím, že SSE operaci rozdělili. V první fázi byl proveden výpočet na dolních 64 bitech (v našem příkladě 5x (2; 3) ) a v druhé fázi pak na horních 64 bit (v našem příkladě 5x (1; 8) ). Celé zpracování tak trvalo dva hodinové cykly, a mělo tak částečně sériový charakter. Navíc na každou z těchto 64bit operací bylo zapotřebí generovat jednu microOP, takže celá operace zabrala v Reorder Bufferu dva záznamy.
Architektura Core jde v tomto dále a zpracovává celých 128 bitů najednou (tedy 5x (2; 3; 1; 8) ). Na celou operaci pak stačí jedna microOP. Díky tomuto vylepšení na úrovni jednotky, díky dekódování SSE instrukcí i v jednoduchých dekodérech, díky snížení požadavků na počet microOPs na polovinu a díky posílení počtu jednotek (viz následující odstavec) dosahuje Core i více než trojnásobného výkonu při zpracování SSE instrukcí. Zejména multimediální aplikace tak zaznamenají s příchodem nové generace procesorů rapidní zrychlení.
Pokračujte
povídání o architektuře Intel Core.



















