

Nejen Nvidia přichází s novým GPU akcelerátorem H100. Intel připravuje své Ponte Vecchio, které má překonávat nynější Nvidii A100. Zajímavé bude např. množstvím paměti. L2 cache má mít 408 MB, paměť HBM2e dokonce 128 GB.
Na trhu s GPU akcelerátory je nyní docela živo. Na Hot Chips 34 poodhalila svou novinku nejen Nvidia (Hopper H100), ale také Intel. Jeho Ponte Vecchio na sebe nechává stále čekat, nicméně nyní už to vypadá, že se přece jen blíží vývoj ke konci a uvedení novinky by se mohlo brzy stát realitou. Ponte Vecchio by mělo být k dispozici v několika variantách. Jeho jednotlivé OAM, subsystém x4 s XE Link a pak jako totéž včetně jedné nebo dvou patic pro procesory platformy Sapphire Rapids.

GPU je v konfiguraci 2-Stack a Intel prezentoval několik zajímavých čísel. V FP64 i FP32 má dosahovat výkonu 52 TFLOPS (Nvidia H100 nabídne 60 TFLOPS), v TF32 je to pak 419 TFLOPS (H100 500/1000 TFLOPS dense/sparse), u FP16 je to pak 839 versus 1000/2000 TFLOPS. Bohužel nevíme, zda Intel udává výkon pro dense nebo sparse výpočty. Výhodou Intelu je mnohem větší paměť HBM2e, která má kapacitu 128 GB místo 80 GB u Nvidie.

Zajímavé hodnoty vidíme u celé paměťové architektury. Intel udává, že Ponte Vecchio má 64MB kapacitu u registrů i L1 cache. Zatímco registry mají datovou propustnost 419 TB/s, u L1 cache je to 105 TB/s. L2 cache má pak obří kapacitu 408 MB (Nvidia H100 50-60 MB dle verze) s rychlostí 13 TB/s. Nakonec tu máme již zmíněných 128 GB paměti HBM2e, která nabídne propustnost 3,2 TB/s. Pro datové přenosy tu máme podporu sběrnice PCIe 5.0.
Co ale vůbec stojí za výkonem Ponte Vecchia? Je to velké GPU, kde se jeden stack skládá z 8 GPU Xe-HPC, má celkem 128 Xe-Core (celkem 16384 jader) a 128 RT jednotek. Využila se zde naplno dlaždicová (chipletová) architektura a máme tu navzájem 47 spojovaných čipů či jiných součástí. Ty jsou vyráběny 3 různými procesy, některé části tak vyrábí Intel pomocí procesu Intel 7, některé pak TSMC na N5 a N7. Ve výsledku tu máme 16 čipů Xe, 8 Rambo, 2 Xe Base, 11 propojení EMIB, 2 Xe Link a 8 paměťových čipů HBM. Celé Ponte Vecchio má obří plochu 4843,75 mm2. Při výrobě se využilo pouzdření 3D Forveros.
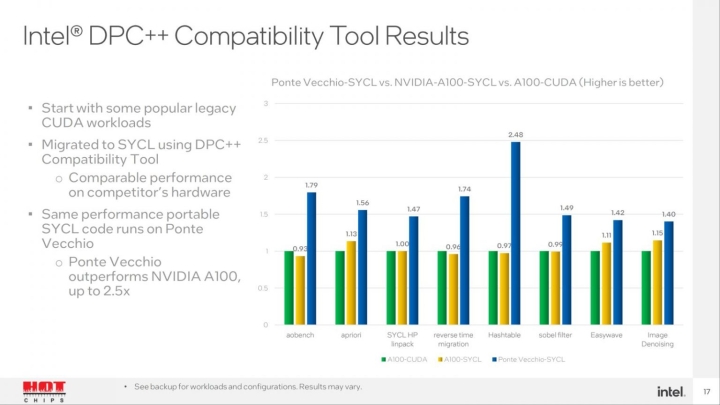
Poněvadž H100 byla ukázána ve stejnou dobu jako Ponte Vecchio, grafy výkonu se logicky vztahují k předchozí Nvidii A100. Proti Nvidii Intel naměřil výkon vyšší o 40 až 148 % (viz graf výše). V miniBUDE měl Intel výkon 2krát vyšší, ExaSMR (NekRS) pak 1,5krát, ExaSMR (OpenMC) byl na dvojnásobku. Zajímavou informací je také vliv L2 cache na výkon. Např. při výpočtu 2D-FFT by snížení velikosti cache ze 408 na 80 MB přineslo jen 53 % výkonu a snížení na 32 MB pak polovinu. U trénování DNN ResNet by tak výrazný rozdíl nebyl, tam to bylo na cca 85 %, resp. 78 %. Co se týče spotřeby, zde se odhaduje okolo 600 W.



















