

Nvidia poodhalila své akcelerátory Hopper H100 s Tensor jádry 4. generace. Tato monstra nabídnou 80 GB paměti s paměťovou propustností 3 TB/s, čip má 80 miliard tranzistorů a počet CUDA jader se už povážlivě blíží 20 tisícům.
Na trhu s HPC GPU akcelerátory má dnes společnost Nvidia velmi výkonné modely A100. Nicméně i ty zblednou závistí nad schopnostmi modelů H100 (Hopper), které byly poodhaleny na Hot Chips 34. Využívají monolitický design a 4nm výrobu u společnosti TSMC (proces 4N). Výsledkem je GPU s 80 miliardami tranzistorů, plochou 814 mm2 a opravdu extrémním výkonem. Plná verze GH100 má celkem 8 GPC, kde každé z nich má 9 TPC, celkem je zde tedy 72 TPC. Každé z nich obsahuje 2 jednotky SM, což znamená celkový počet 144 SM. Aby té matematiky nebylo málo, každé SM obsahuje 128 CUDA jader, takže v "plné palbě" tu máme 18432 CUDA jader.

Nvidia dále použila Tensor jádra 4. generace, přičemž na celé GPU jich je tu 576. Dostáváme zde paměť HBM3 nebo HBM2e a 12 512bitových paměťových řadičů. To také znamená, že paměťová propustnost zde činí 3 TB/s. Pro představu, nové GeForce RTX řady 4090 by měly mít něco okolo 1,15 TB/s. Aby toho nebylo málo, dostalo se také na 60 MB L2 cache, NVLink 4. generace (900 GB/s) a podporu PCIe Gen5.
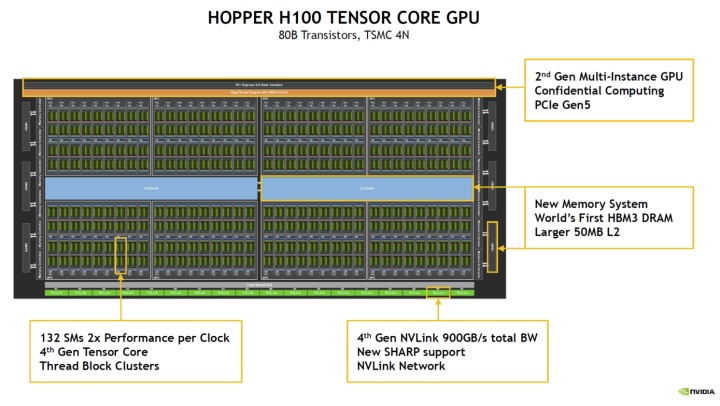
V případě Nvidia H100 ve formátu SXM5 se specifikace trochu sníží, bude tu 66 TPC a celkem 132 SM, což se také projeví poklesem počtu CUDA jader na 16896. Také počet Tensor jader mírně klesne na 528. Sníží se také počet 512bitových řadičů paměti na 10 a paměť L2 cache bude mít 50 MB. PCIe verze bude množství dále snižovat na 57 TPC a 114 SM, počet CUDA jader bude 14592 a najdeme tu 456 Tensor jader. V jejím případě také klesne TDP na 350 W, zatímco ostatní verze budou mít 700 W.
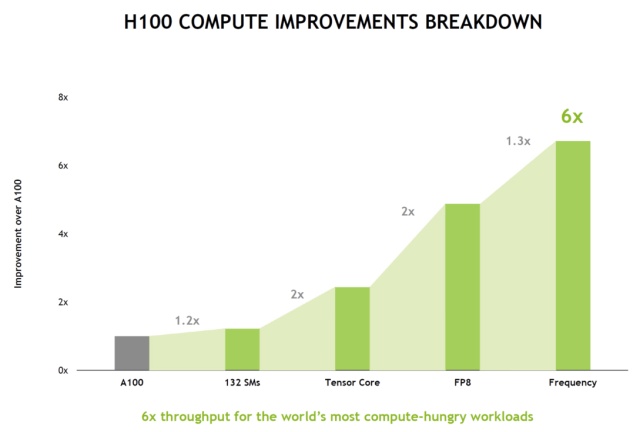
Proti A100 mohou nové karty dosahovat až 6× vyššího výkonu v FP8. Samotné navýšení počtu SM se podílí jen na 20% navýšení výkonu. Tensor jádra ale výkon navyšují hned dvojnásobně a totéž platí pro výkon v FP8 na jádro. Nakonec je tu i vyšší frekvence, která přidává dalších 30 % k dobru. V FP8 se lze těšit na výkon 4000 TFLOPS, v FP16 jde o 2000 TFLOPS, TF32 nabídne 1000 TFLOPS a FP64 pak 60 TFLOPS. Obecně by ale H100 měla být proti A100 2,25× výkonnější. Máme zde také možnost asynchronního zpracování dat, což má až 7násobně zkrátit latence. Pokud jde o zpracování v FP8, podporovány jsou režimy E5M2 i E4M3, kdy si lze vybrat, kolik bitů bude vyhrazeno pro exponent a kolik pro mantisu. Exponent můžete mít 4 nebo 5 bitů, mantisa pak 3 nebo 2 bity.


















