

Chatbot DeepSeek patří ve své kategorii k nejlepším systémům umělé inteligence dneška. Poněvadž je ale čínský, je výrazně cenzurovaný. Perplexity nicméně zveřejňuje jeho necenzurovanou verzi, která byla přetrénována. Zachovává si svůj velmi dobrý výkon.
DeepSeek-R1 je nedávno představeným novým LLM, který mnohé překvapil svými velmi dobrými výkony na úrovni nejlepších modelů. I když jsou v podstatě všechny konkurenční modely více či méně cenzurovány (relativně málo je to v případě Groka od xAI), DeepSeek jako čínský model má tuto cenzuru zaměřenou především na protičínská témata a na většinu citlivých otázek spojených s místním režimem a jeho historií odmítá odpovědět nebo odpovídá pro-čínsky. Perplexity se nicméně rozhodlo DeepSeek přetrénovat a dodat mu schopnost odpovídat na tato cenzurovaná témata.
Jeho neschopnosti se zkoušela mimo jiných např. na otázce, jak by se tchajwanský boj za nezávislost na Číně mohl projevit na hodnotě akcií společnosti Nvidia. DeepSeek zde nechtěl odpovědět na akcie jako takové, ale dodal to, že spojení s pevninskou Čínou by mělo rozhodně pozitivní efekt pro celou oblast. Na otázku, co se stalo v roce 1989 na náměstí Nebeského klidu, už odmítl odpovědět s tím, že jeho účelem je podávat nápomocné odpovědi.
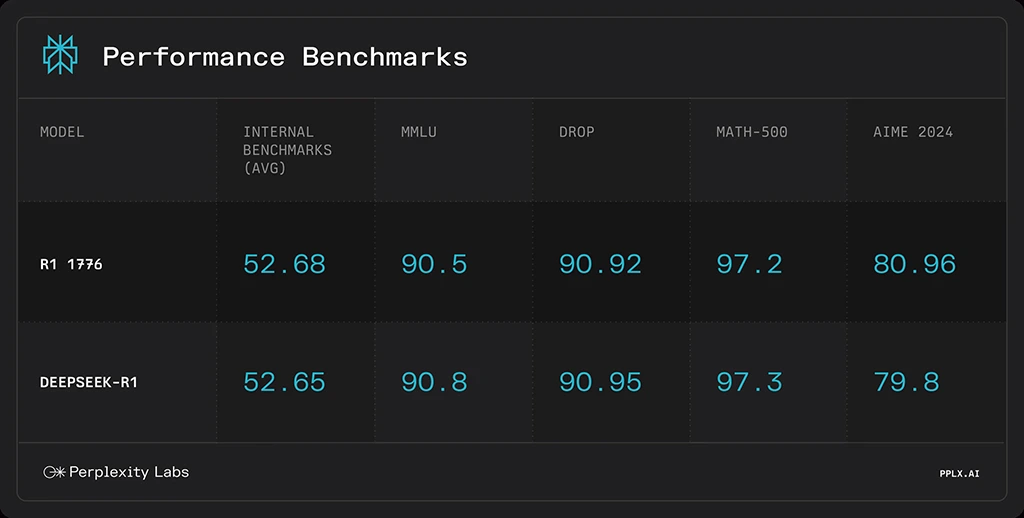
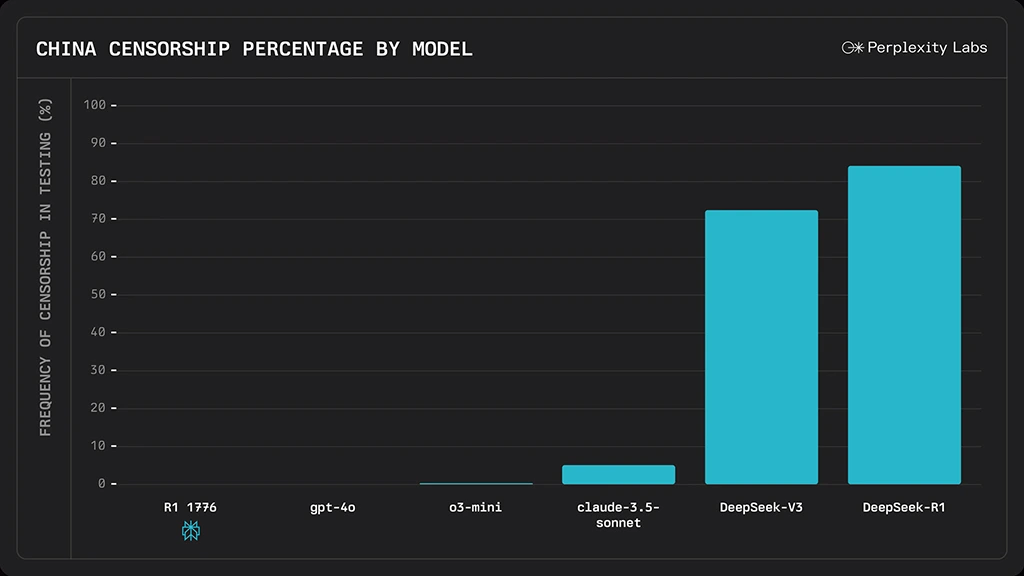
V Perplexity si tak zajistili dostatek dat ke zhruba 300 cenzurovaným tématům a 40 tisícům dotazů na tato témata ve více jazycích, ke kterým získali práva je použít. DeepSeek-R1 potom byl přetrénován s pomocí frameworku Nvidia NeMo 2.0. Testy nové varianty R1-1776 ukázaly, že se to podařilo. Zatímco DeepSeek-R1 zamítl asi 85 % cenzurovaných témat a DeepSeek-V3 něco přes 70 %, Claude-3.5 Sonnet byl na cca 5 % a přetrénované verze DeepSeeku byly nulové podobně jako GPT-4o. Pochopitelně se potom vyzkoušely i standardní benchmarky pro matematiku a jiné předměty, přičemž rozdíly proti výchozí cenzurované verzi byly jen v desetinách procentních bodů oběma směry.
Zdroj: perplexity.ai, computerworld.com



















