

Vícejádrové procesory si vyžádaly nový přístup Intelu k propojení jejich interních částí. AMD ve svých moderních procesorech využívá Infinity Fabric vyvinutou z Hypertransportu a Intel nově mluví o Mesh Interconnect v procesorech Xeon Scalable.
Řada procesorů Intel zahrnutá pod Xeon Scalable bude nabízena jako přímá konkurence pro platformu AMD Naples, čili až 32jádrové procesory EPYC. Intel ale nový Mesh Interconnect nabídne i v rámci HEDT procesorů Skylake-X. Mluvíme tak o náhradě architektury nazývané ringbus, která byla součástí procesorů Intel už od roku 2011, kdy přišla generace Sandy Bridge.
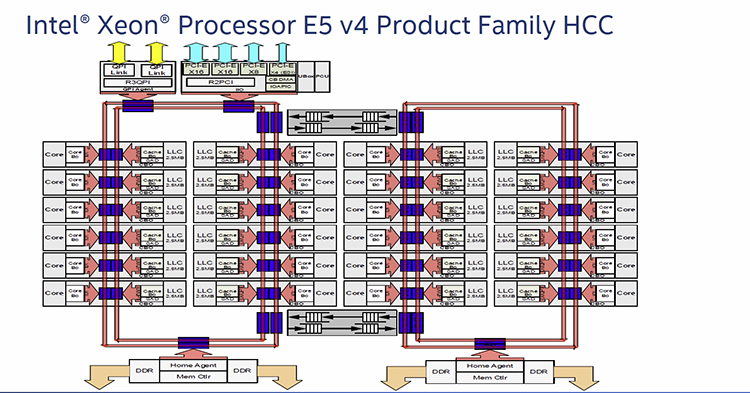
Ringbus na procesorech Xeon E5 v4
Ringbus fungovala dobře v době, kdy počet jader v procesorech ještě nebyl tak vysoký, ale ten postupně roste, a to především v serverovém světě, ale i HEDT procesory Intelu se brzy dostanou na 18 fyzických jader. Pak už je velice těžké zajistit, aby Ringbus poskytl vysokou datovou propustnost a nízké latence, takže Intel musel chtě nechtě přijít s novým přístupem.
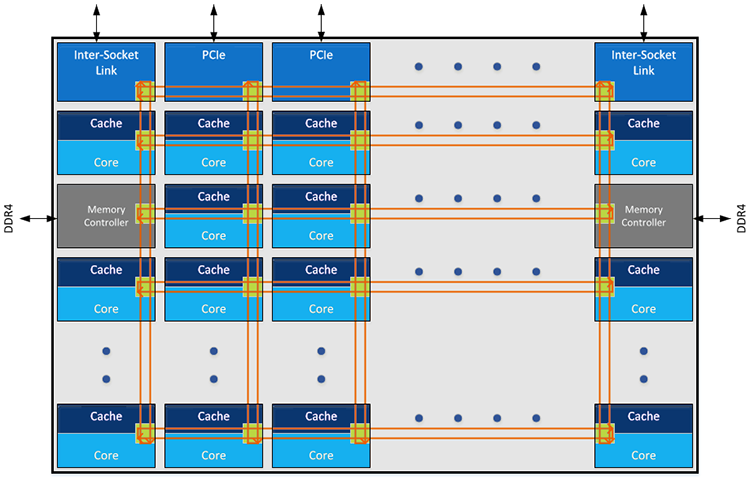
Mesh Interconnect
Intel tak už nechtěl navyšovat počet datových zastávek v "okruhu" interní sběrnice procesorů a přišel namísto nich s "pletivem" čili Mesh Interconnect, které bude spojovat všechno se vším. To znamená jednotlivá procesorová jádra s jejich vlastní pamětí cache i další uncore části, jako jsou paměťové kontrolery, rozhraní PCI express, L3 cache, atd. Celkový počet datových spojů tak bude přímo záviset na počtu jader, kanálů pro paměti a dalších částí procesoru, takže je zřejmé, že jde o architekturu, která je ze své podstaty škálovatelná.
Nejde ale o zcela symetrickou architekturu. Pokud si například jedno jádro vyžádá data z paměti L3 cache napojenou pomocí Mesh Interconnect "vertikálně", pak to znamená přístup v jednom cyklu, čemuž odpovídá i zpoždění. Pokud je ale tato cache napojená v horizontálním směru, pak bude zpoždění odpovídat třem cyklům. To přitom platí pro případ, kdy procesorové jádro a L3 cache přímo sousedí, přičemž čím více skoků je třeba překonat, tím větší zpoždění nastane. Podle Intelu je však tato architektura i tak celkově mnohem lepší než Ringbus, pokud je nasazena v procesorech s vyšším počtem jader.
Výhoda má spočívat také v nižší spotřebě v porovnání s Ringbus, protože Mesh Interconnect si vystačí s nižším taktem i napětím. To znamená, že větší část energie může být přesunuta k jádrům, v čemž můžeme vidět paralelu s GPU a paměťmi HBM. Ty také už v případě čipů AMD Fiji měly výrazně nižší spotřebu než GDDR5, což umožnilo ušetřenou energii využít v samotném GPU.
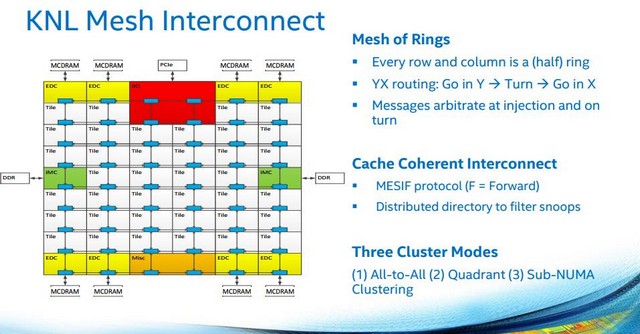
Mesh Interconnect má pracovat na podobném taktu jako jiné uncore části, což znamená cca 1,8 až 2,4 GHz a dostupné materiály ukazují, že procesory budou mít obvyklé uspořádání, kde uprostřed budou samotná procesorová jádra a uncore části budou u krajů.























