
Seznam kapitol
Spotřeba procesorů a grafických karet roste. Není to tak dávno, kdy jsme si od menších tranzistorů slibovali vyšší frekvence a nižší spotřebu. To je dnes minulost. V první části se podíváme, co ovlivňovalo výkon v minulosti a jak inovace zvyšovaly spotřebu.
Architektura čipů Minulost nám přinesla procesory s taktem 3 MHz, ale i ty s taktem 1000 MHz (a už je to docela dlouho). Nezvyšovala se jenom frekvence, ale i počet tranzistorů.
Staré procesory byly z dnešního pohledu velmi primitivní. Čip přebíral z binárního souboru programu požadované instrukce a dostupná data a tyto prováděl v přesně stanoveném pořadí (in-order execution). Výsledná efektivita (rychlost programu) závisela více méně pouze na algoritmu výpočtu a frekvenci čipu. Pokud programátor vymyslel rychlý algoritmus, program chodil rychle, v opačném případě chodil pomalu. Optimalizace na úrovni hardware prakticky neexistovaly. Výhodou této koncepce je jednoduchý návrh procesoru (který byl ve své době hlavním požadavkem - vyráběly se "velké" transistory a ani ne masově, zrovna levné to tedy nebylo), nevýhodou naopak to, že výkon s rostoucí frekvencí příliš neroste. Důvod, proč výkon neroste, je ten, že jakmile dojde k čekání na dostupnost dat, vykonávání instrukcí je pozastaveno. Jinými slovy pokud procesor chce vykonat instrukci a data k ní příslušná jsou ještě v paměti (nebo ještě hůře na pevném disku), výpočet se zastaví. Protože jsou instrukce vykonávány v předem daném pořadí, dokud není hotova jedna instrukce, nezačnou se ani vykonávat jiné. Výkon je v tomto případě hrozný.
Pipeline
Jedním z prvních problémů, na který výrobci narazili, byla rychlost elektronů - přesněji vzato elektrické pole, samotné elektrony se pohybují dost pomalu. Přestože jsou procesory velmi malé a rychlost relativně vysoká (300 tisíc kilometrů za vteřinu ve vakuu), je při vysoké frekvenci cesta, kterou musí v čipu urazit, velmi dlouhá. U 1 GHz procesoru trvá jeden hodinový cyklus 0,000000001 vteřiny, neboli jednu nanosekundu (u dvougigaherzového je to půl nanosekundy). Za dobu 1ns urazí pole vzdálenost 30 centimetrů - toto platí ve vakuu, v polovodičích to může být výrazně méně. A i kdyby ne, ve změti milionů až desítek milionů vzájemně propletených transistorů je to příliš málo.
Řešením je pipelining. O co jde? Průběh instrukce je rozdělen na řadu stupňů, z nich každý je vykonáván v rozdílném hodinovém cyklu.
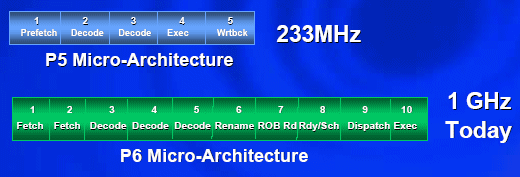
Původní procesor Pentium, stejně jako 486ky, má pětistupňovou pipeline. První stupeň je dodávka instrukcí a dat, druhý stupeň dekódování, třetí stupeň druhá fáze dekódování, čtvrtý stupeň vykonávání (výpočet operace) a pátý stupeň zápis výsledku. Když je zpracování programu spuštěno, průběh vypadá takto:
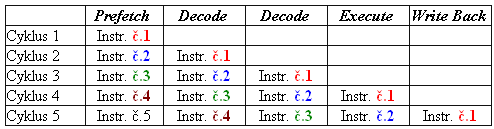
Po pěti hodinových cyklech je instrukce č. 1 hotová, instrukce 2 má jeden cyklus do dokončení... instrukce 5 proběhla prvním stupněm. Takto je možné snadno vyřešit problém s nedostatečnou rychlostí elektronů a zvýšit tak frekvenci čipu. Výsledný výpočetní výkon je totiž stejný bez ohledu na to, kolik stupňů pipeline má - vždy v jednom cyklu dojde k dokončení jedné instrukce. Protože však takto rozkouskovaný výpočet je možné provádět při mnohem vyšších frekvencích...
Pipelining má bohužel i stinné stránky. Nevýhodou je, že pakliže je jedna instrukce datově závislá na druhé (jinými slovy jedna instrukce má k sobě data, která jsou výsledkem instrukce jiné), tuto instrukci nelze vykonat, dokud nebude výsledek instrukce první známý... a to může při pipelinovém způsobu zpracování trvat několik cyklů. Nebo: Instrukce má k sobě data uložená na nějaké adrese v paměti. Adresa je výsledkem nějaké operace (např. předchozí adresa + 10 byte). V takovém případě opět nelze instrukci vykonat, dokud nejsou spočítány předchozí operace vedoucí k zjištění adresy. Čím delší pipeline, tím víc takovýchto "příhod" se může stát. V pipeline tak vznikají prázdná místa ("bublinky"), která snižují výkon. Za ne zcela ideálních podmínek (= vždy) platí, že čím delší pipeline, tím nižší výkon při stejné frekvenci.
Superskalár
Neustálé zvyšování frekvence bylo při 486kovém způsobu vykonávání instrukcí nepříliš efektivní. Jak se zvyšovala frekvence, tak také rostly požadavky na přísun dat. Procesory byly stále výrobně drahé, proto neměly příliš mnoho vyrovnávací paměti cache, a tak v extrémních případech dvojnásobná frekvence mohla znamenat, že procesor pouze dvojnásobné množství hodinových cyklů čekal na data z paměti, která byla stejně rychlá bez ohledu na frekvenci procesoru. Naopak v jiných, výpočetně náročných případech procesor často "makal" naplno, ale i tak to nebylo moc rychlé. Zvyšovat frekvenci také nešlo do nekonečna.
Z hlediska počtu jednotek bychom mohli Itanium 2 nazvat "hyperskalár"
Po určité době někoho napadlo, že by možná nebylo od věci umístit do procesoru více stejných výpočetních jednotek a začít provádět výpočty paralelně, čímž by se v některých případech výkon značně zvýšil. Intel toto učinil v procesoru Pentium. I ten je z dnešního pohledu poměrně primitivní, namísto jedné jednotky pro výpočet celých čísel (ALU - Arithmetic Logic Unit) má dvě. Instrukce i tak vykonává v předem daném pořadí, jen místy vykoná dvě po sobě jdoucí instrukce vedle sebe ve stejný okamžik (každou v jiné ALU jednotce). Důvod, proč Intel šel do paralelního vykonávání instrukcí, byl vcelku zřejmý - procesor 486 DX4 měl cca. jeden a půl milionu transistorů a s frekvencí končil na 100 MHz. Se stejnou výrobní technologií jelo Pentium na stejné frekvenci jako 486 DX4, přičemž díky dvěma jednotkám pracovalo běžně o 50 procent rychleji. Dvojnásobné množství transistorů (a tudíž prakticky dvojnásobná výrobní cena) nebylo až tak určující, Intel získal obrovský náskok před konkurencí. Navíc - během jednoho roku nová výrobní technologie umožnila chrlit Pentia ve velkém množství.
Out-of-order a spekulativní vykonávání instrukcí
Protože vykonávání instrukcí v určeném pořadí mělo určitá slabá místa ve využití výpočetních jednotek, vymyslel Intel procesor Pentium Pro (architektura P6). Ten kromě integrace další úrovně cache přímo k výpočetní části také zavedl out-of-order execution (zpracování instrukcí mimo pořadí). Procesor vnitřně pracuje s malým množstvím instrukcí zvaných microOPs, nebo také jen OPs (jedná se o RISC jádro), kde na začátku pipeline jsou instrukční dekodéry - ty přijímají instrukce a vytvářejí z nich OPs - instrukce pro vnitřní RISCové jádro. Uvnitř si jádro organizuje OPs podle potřeb, a provádí tak instrukce mimo programátorem stanovené pořadí... v mezích bariér daných závislostí jednotlivých instrukcí. Nárůst výkonu je proti in-order způsobu často extrémní. Nevýhodou ale je, že takto navrhnutý čip je již velmi složitý a může také obsahovat velmi mnoho chyb.
Druhou vlastností, kterou bylo Pentium Pro obdařeno, bylo vykonávání instrukcí po podmínce, tzv. spekulativní spouštění kódu. Podmínky v programech mají velmi negativní vliv na výkon. Situace vypadá tak, že v případě splnění podmínky se provádí kód A, v případě nesplnění kód B. Problém je, že procesor nezná výsledek podmínky, dokud jí nevypočítá. Protože podmínka je v cca. 99 procentech případů vázána na výpočty provedené v kódu těsně před podmínkou, znamená to, že podmínka výrazně zbrzdí superskalární vykonávání instrukcí - způsobí tzv. pipeline stall ("bublinky"), kdy instrukce nejsou vykonávány, protože se čeká na výsledek instrukce jiné (na výsledek podmínky). Pentium Pro umí odhadnout výsledek podmínky - a to s úspěšností 90 procent nebo více. Toto je již tak trochu magie, neptejte se mě, jak to provádí. Po odhadnutí výsledku podmínky je vykonán příslušný kód - v našem příkladu třeba kód A. Postupně jsou vykonávány instrukce kódu A a také instrukce před podmínkou - až je určen přesný stav podmínky. V případě, že odhad podmínky byl správný (většina případů), procesor již má dopředu vypočítánu velkou část kódu A. Avšak pokud byla podmínka odhadnuta špatně, musí se všechny výsledky zapomenout a začít počítat kód B. Protože v takovém případě je v okamžiku vypočtení podmínky pipeline plná instrukcí kódu A, chvíli trvá, než procesor dojde k prvnímu výsledku kódu B - čím více stupňů pipeline má, tím hůř, protože tím více cyklů to trvá. Tato časová prodleva se nazývá misprediction penalty.
Některé procesory jsou navrženy tak, aby vykonávaly obě větve po podmínce s tím, že jednu z nich po vyhodnocení výsledku podmínky zapomenou.


















