

NVIDIA dnes zveřejnila na svém blogu také podrobné informace o tom, z čeho se skládá nový čip A100 generace Ampere, který je vytvořen 7nm procesem v TSMC a obsahuje na 54 miliard tranzistorů.
Dvě verze Amperu
Samozřejmě se nepočítá s tím, že by A100 byly běžně vyráběny bezchybně, takže ačkoliv skutečně obsahují 8192 CUDA jader, jak je uvedeno v titulku, ne všechna musí být aktivní. Vysoce paralelizovaná architektura má onu obvyklou výhodu v tom, že část čipu vyrobená s chybou se může vypnout (pokud nejde o problém v jinak nenahraditelné oblasti) a čip se může dále používat, což ostatně dnes platí i pro procesory, i když v omezené míře.
Ve skutečnosti je něco takového už zcela nutné, a to zvláště u čipu jako A100, v jehož případě se všech 54 miliard tranzistorů těžko vyrobí zcela bezchybně. Z celkového počtu 8192 FP32 CUDA jader ale je co ubírat a NVIDIA může na hůře vyrobených A100 stavět i jiné produkty než plnohodnotné Tesly.
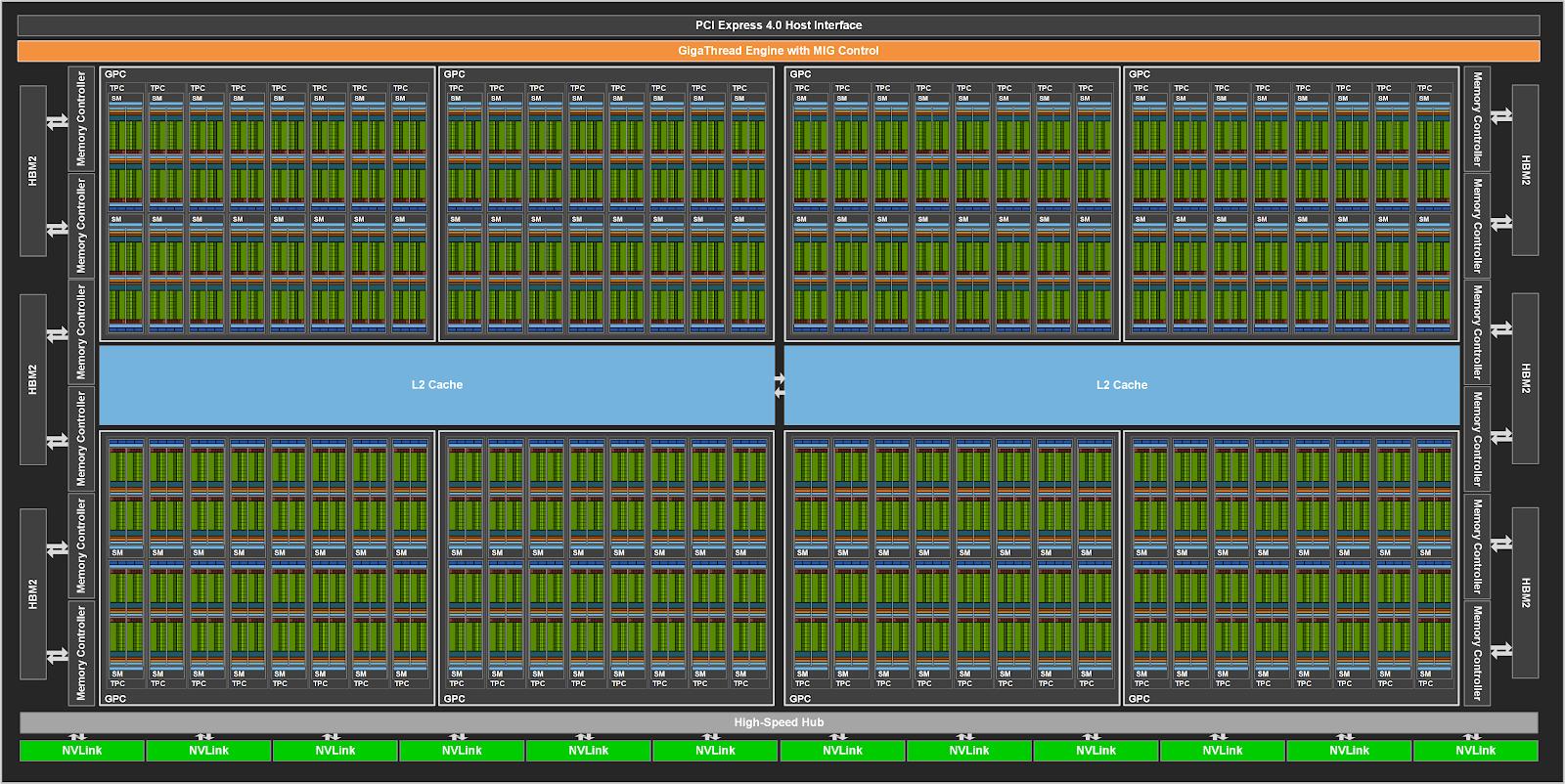
konfigurace plnohodnotného čipu Ampere A100 - klikněte pro zvětšení -
Co se týče plné verze GA100, ta se skládá z celkem osmi GPC (GPU Processing Cluster), z nichž každý zahrnuje svých osm TPC (Texture Processing Cluster), v každém TPC jsou dva SM (Streaming Multiprocessor) a těch je tu tak 128 v celém GPU. V jednom SM máme celkem 64 klasických CUDA jader pro FP32, takže jejich celkový počet se vyšplhal na 8192 a celé GPU má také 512 jader Tensor 3. generace (4 na SM). Paměťové kontrolery pro HBM2 jsou rozděleny na dvanáct 512bitových jednotek, čili dohromady to dělá očekávaných 6144 bitů pro 48 GB paměti.
Ovšem implementace A100 Tensor Core bude slabší a nabídne "pouze" 108 SM po 64 CUDA jádrech v celkem 7 GPC, čili 6912 CUDA jader na celé GPU, takže cca 84 procent z celkové nabídky čipu. Tomu odpovídá i výbava 432 jader Tensor a slabší bude také paměťový subsystém s pěti pouzdry HBM2, a tedy odpovídajícími deseti 512bitovými segmenty kontroleru pro 40 GB paměti.
Čili prostě a jednoduše, GA100 bude plnotučný Ampere s 8192 CUDA jádry a A100 osekaná verze se 6912 CUDA jádry.
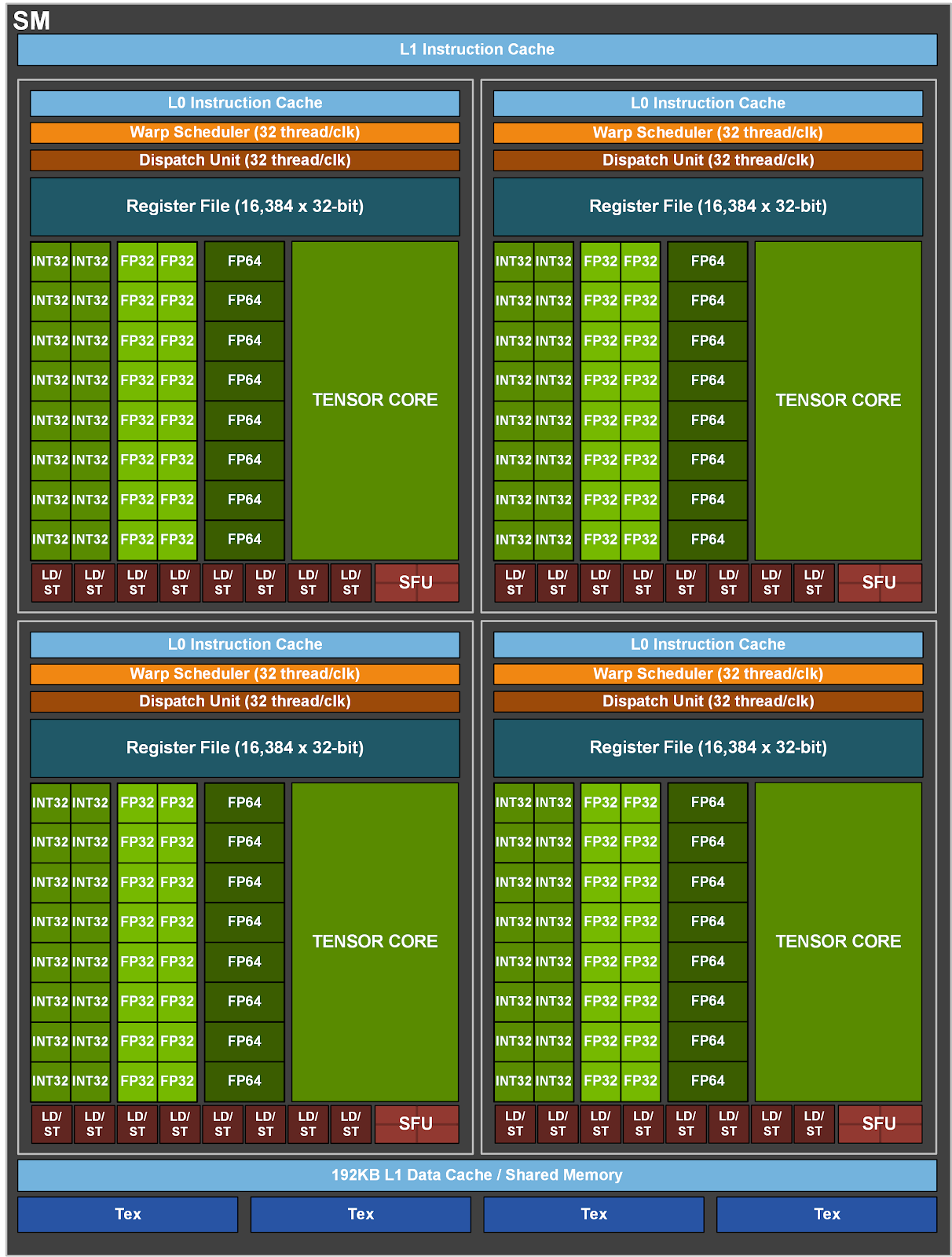
jednotka SM generace Ampere
Co se týče nových jader Tensor, pak ty se od předchozích verzí v čipech Volta a Turing zásadně liší. Starší Tensor zvládají celkem 64 operací v FP16/FP32 (mixed precision FMA - Fused Multiply-Add) za sekundu. Každé Tensor třetí generace v Ampere zvládne 256 FP16/FP32 FMA operací za takt a se čtyřmi Tensor jádry na SM to znamená dvojnásobný výkon na SM oproti generacím Volta a Turing.
Nová jádra Tensor zvládnou zpracovávat všechny typy dat včetně FP16, BF16, TF32, FP64, INT8 a INT4, mají novou funkci sparsity pro využití "řídkosti" v hlubokých neuronových sítích pro zdvojnásobení výkonu ve standardních Tensor Core operacích.
Výkon a specifikace
| Formát | V100 | A100 | A100 Sparsity | Nárůst výkonu A100 | Nárůst výkonu A100 se Sparsity |
| A100 FP16 vs. V100 FP16 | 31,4 TFLOPS | 78 TFLOPS | N/A | 2,5x | N/A |
| A100 FP16 TC vs. V100 FP16 TC | 125 TFLOPS | 312 TFLOPS | 624 TFLOPS | 2,5x | 5x |
| A100 BF16 TC vs.V100 FP16 TC | 125 TFLOPS | 312 TFLOPS | 624 TFLOPS | 2,5x | 5x |
| A100 FP32 vs. V100 FP32 | 15,7 TFLOPS | 19.5 TFLOPS | N/A | 1,25x | N/A |
| A100 TF32 TC vs. V100 FP32 | 15,7 TFLOPS | 156 TFLOPS | 312 TFLOPS | 10x | 20x |
| A100 FP64 vs. V100 FP64 | 7,8 TFLOPS | 9,7 TFLOPS | N/A | 1,25x | N/A |
| A100 FP64 TC vs. V100 FP64 | 7,8 TFLOPS | 19,5 TFLOPS | N/A | 2,5x | N/A |
| A100 INT8 TC vs. V100 INT8 | 62 TOPS | 624 TOPS | 1248 TOPS | 10x | 20x |
| A100 INT4 TC | N/A | 1248 TOPS | 2496 TOPS | N/A | N/A |
| A100 Binary TC | N/A | 4992 TOPS | N/A | N/A | N/A |
Dále se ještě podíváme na specifikace verze A100 v porovnání s Teslou V100 i P100.
| Data Center GPU | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA A100 |
| GPU kódový název | GP100 | GV100 | GA100 |
| GPU architektura | NVIDIA Pascal | NVIDIA Volta | NVIDIA Ampere |
| GPU formát | SXM | SXM2 | SXM4 |
| SM | 56 | 80 | 108 |
| TPC | 28 | 40 | 54 |
| FP32 Cores / SM | 64 | 64 | 64 |
| FP32 Cores / GPU | 3584 | 5120 | 6912 |
| FP64 Cores / SM | 32 | 32 | 32 |
| FP64 Cores / GPU | 1792 | 2560 | 3456 |
| INT32 Cores / SM | - | 64 | 64 |
| INT32 Cores / GPU | - | 5120 | 6912 |
| Tensor Cores / SM | - | 8 | 42 |
| Tensor Cores / GPU | - | 640 | 432 |
| GPU turbo | 1480 MHz | 1530 MHz | 1410 MHz |
| Texture Unit | 224 | 320 | 432 |
| Paměťové rozhraní | 4096-bit HBM2 | 4096-bit HBM2 | 5120-bit HBM2 |
| Kapacita pamětí | 16 GB | 32 GB / 16 GB | 40 GB |
| Takt pamětí | 703 MHz DDR | 877,5 MHz DDR | 1215 MHz DDR |
| Celková propustnost | 720 GB/sec | 900 GB/sec | 1,6 TB/sec |
| L2 Cache | 4096 KB | 6144 KB | 40960 KB |
| Shared Memory / SM | 64 KB | až 96 KB | až 164 KB |
| Register File / SM | 256 KB | 256 KB | 256 KB |
| Register File / GPU | 14336 KB | 20480 KB | 27648 KB |
| TDP | 300 W | 300 W | 400 W |
| Počet tranzistorů | 15,3 mld | 21,1 mld | 54,2 mld |
| Velikost GPU | 610 mm² | 815 mm² | 826 mm² |
| Výrobní proces (vše TSMC) | 16 nm FinFET+ | 12 nm FFN | 7 nm N7 |
Důležité údaje, které se ještě nikde neukázaly, jsou o taktu GPU, spotřebě a velikosti GPU. Takt zůstal víceméně na stejné úrovni, ale přesto je nižší než v případě Pascalu i Volty. Dalo by se tak očekávat, že ani herní Ampere nebudou zvyšovat takty oproti Turingu, ale uvidíme.
Příliš ne nezvýšila ani rozloha čipu, což je výtečná zpráva, neboť na téměř stejnou plochu se NVIDII a TSMC podařilo nacpat více než 2x více tranzistorů. Pokud by tedy i herní Ampere měly mít podobně velké čipy, tak by šlo očekávat skutečně velký pokrok. A co se týče TDP, to šlo nahoru o třetinu na 400 W, čemuž se skutečně vzhledem ke specifikacím nelze divit.
Architektura MIG
Nakonec nebudeme mluvit o ruském leteckém inženýrství, ale o CSP Multi-Instance GPU, čili MIG v podání NVIDIE. Jde o již zmíněnou schopnost nabídnout jedno GPU A100 celkem sedmi uživatelům s tím, že každý z nich může očekávat výkon srovnatelný s GPU V100.
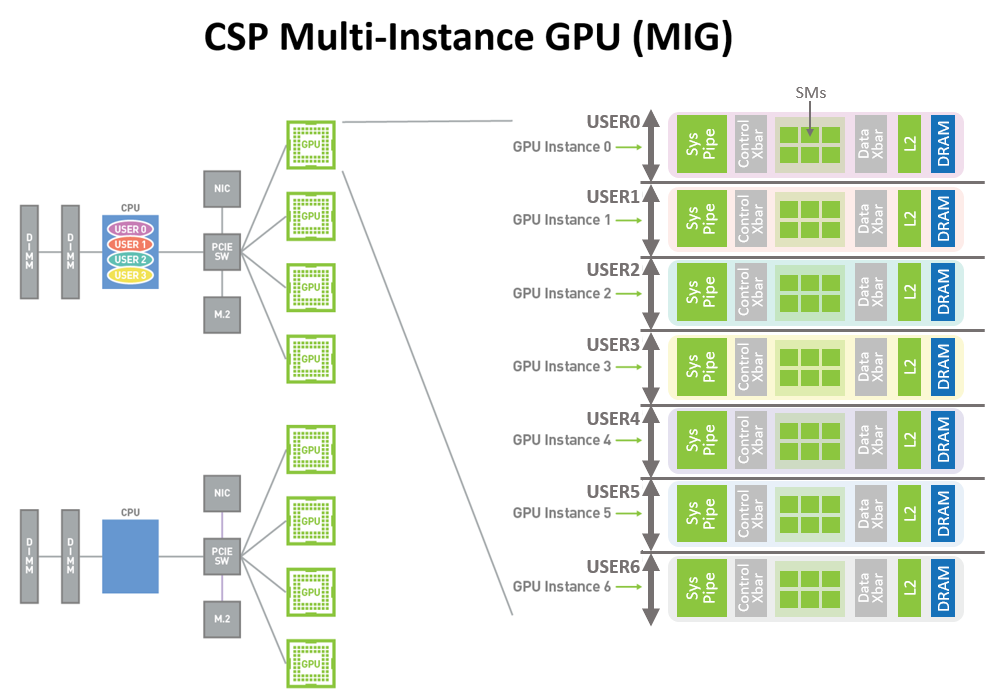
Jde tak pochopitelně o případ, kdy někdo skutečně nepotřebuje výkon celého A100, takže MIG poslouží pro účely efektivity v případě menší zátěže. Takové GPU instance generace Volta v rámci Multi-User Node ještě nenabízela a je zřejmé, že NVIDIA musela vyřešit i to, aby data jednotlivých instancí byla zcela oddělena, přičemž NVIDIA to dle vlastních slov nedělá kvůli tomu, aby nevytvořila GPU verzi exploitů Spectre a Meltdown.
Jde jí především o kvalitu služeb, čili aby vyhrazená část GPU sloužila skutečně jen jednomu uživateli a nestalo se, že by sdílené prostředky GPU někdo zasedl jako žába na prameni. Provozovatel tak bude moci vždy nabídnout jasně definovaný výkon s datovou propustností a latencemi, jakkoliv si další uživatelé stejného GPU zahltí či nezahltí své vlastní instance. Čili každá instance má své vlastní oddělené a izolované datové cesty, L2 cache, paměťové kontrolery, atd.
Zde si pak můžete přečíst o AI inovacích na A100 a podívat se také na nového průvodce pro programování pro CUDA, který už má brát v potaz nově představenou verzi CUDA 11. My uvidíme, zda z onoho kvanta dnes zveřejněných informací nevykrystalizují také nějaké zajímavosti o tom, jaká by mohla být příští generace GeForce. Spekulací bude jistě dost.


















