Trénování systémů umělé inteligence je v poslední době velké téma a Intel je prozatím jediným, kdo má výsledky v novém benchmarku MLPerf pro trénování GPT-3. Navíc na září slibuje výkonnostní vzpruhu díky vylepšenému softwaru.
Umělá inteligence zasahuje do stále více technologií, které používáme v našich životech. Poslední dobou se do popředí dostává i generativní AI, především systémy založené na GPT. Drtivou většinu trénování takových systémů mají na starosti GPU od Nvidie, jejichž podíl vzrostl už na 95 %. Své chce ale říci i AMD (to nedávno představilo Instinct MI300) a Intel, který před několika týdny představil svůj čip Habana Gaudi2 (ten má na starosti Habala Labs, která nyní spadá pod Intel).

Právě tento čip je jedním z mála, který se objevil v databázi výsledků benchmarku MLPerf od ML Commons. Tam je několik různých testů a nedávno zde právě přibyla i kolonka pro trénování generativní AI založené na systému GPT-3. Další systémy, které mají výsledky v databázi pro trénování GPT-3, pak byly založeny na 80GB verzích Nvidia X100-SXM-5. Bude Intel stačit Nvidii, která je v podstatě téměř jediným používaným řešením?
Zde ještě připomeňme, že Intel Gaudi2 proti první generaci přešel ze 16nm na 7nm výrobní proces, počet Tensor Processor Cores pro zpracování algoritmů AI se zvýšil z 8 na 24, přibyla podpora FP8 a také se 3násobila kapacita pamětí HBM2e na 96 GB, přičemž ta má propustnost 2,45 TB/s.
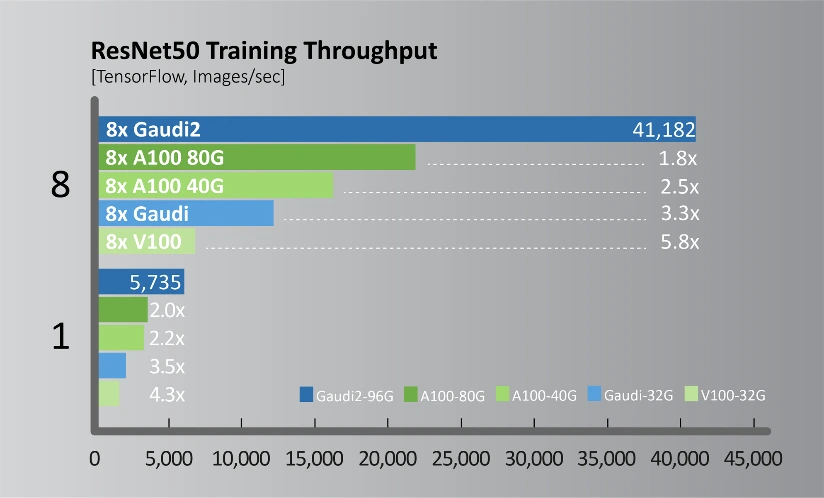
Při své prezentaci se Intel nepřekvapivě soustředil na ty testy, ve kterých byl lepší, a tak např. klasifikace obrázků přes model ResNet50 přináší proti 80GB verzi Nvidia A100 o 80 % lepší výkon. Zde ale připomeňme, že novější Nvidia H100 má dle Nvidie i většiny benchmarků v této úloze zhruba okolo 90 % vyšší výkon, takže nový Intel na ni těsně nestačí. Jenže na H100 se zde zapomnělo.
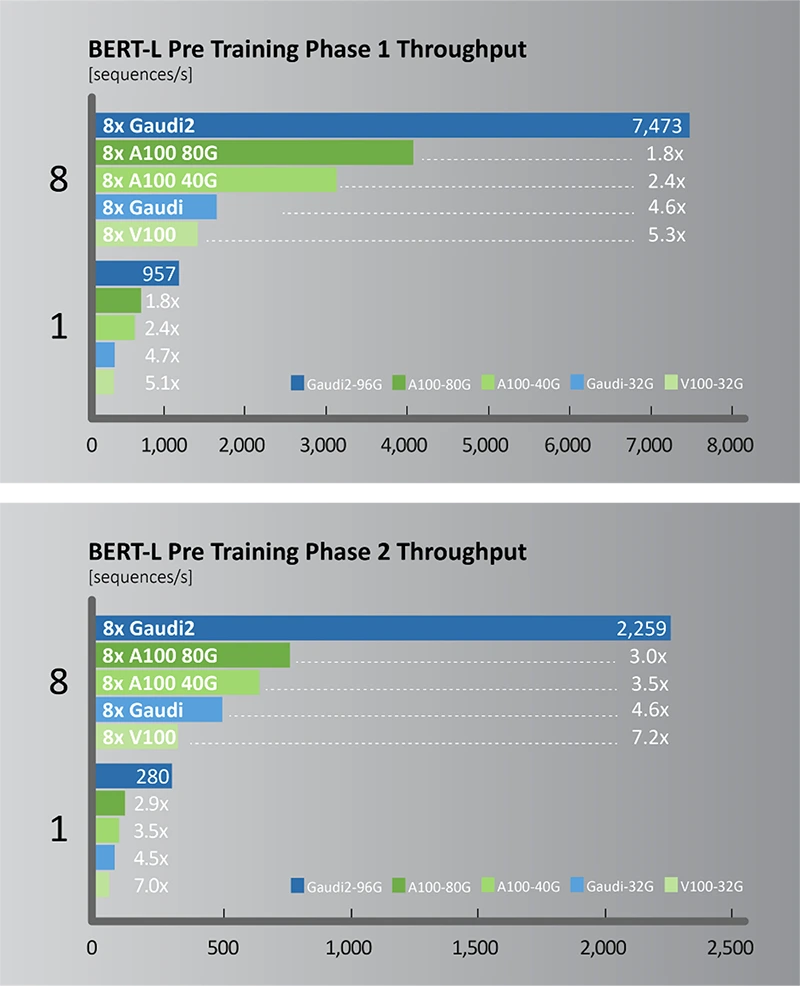
Podobné výsledky máme i u trénování NLP BERT-L. Proti A100 má Intel 80% náskok, proti 40GB verze Nvidie dokonce 140% (má 2,4krát tolik výkonu). Bohužel Intel opět opomněl použít Nvidii H100, která má proti A100 v této úloze obvykle cca 3násobný výkon.
Ale jak je na tom trénování LLM, tedy systémů jako GPT-3? Nvidia tu má celkem 5 záznamů s akcelerátory H100-SXM-5-80GB. Se 128 akcelerátory H100 bylo potřeba 64,3 minuty na natrénování, s 896 takovými akcelerátory to pak bylo 10,9 minuty. Vidíme, že to neškáluje úplně perfektně, ale můžeme si dovolit odhady v tom, kolik by to trvalo jednomu takovému akcelerátoru za předpokladu perfektního škálování.
| Počet akcelerátorů Nvidia H100 |
Dosažený čas (minut) |
Odhadovaný čas pro 1 akcelerátor (za předpokladu perfektního škálování) |
| 128 |
64,264 min |
8225,8 min |
| 192 |
44,816 min |
8604,7 min |
| 192 |
45,606 min |
8756,4 min |
| 384 |
23,611 min |
9066,6 min |
| 896 |
10,940 min |
9802,2 min |
Jak je vidět, škálování není dokonalé, protože 7násobné zvýšení počtu akcelerátorů (ze 128 na 896) nesrazilo čas na sedminu. Jinak řečeno, čas 128 akcelerátorů není 7krát delší, ale jen 5,87krát. Každopádně se dá předpokládat, že jedna H100 by na tuto úlohu pravděpodobně potřebovala pod 8000 minut.
| Počet akcelerátorů Intel Habana Gaudi2 |
Dosažený čas (minut) |
Odhadovaný čas pro 1 akcelerátor (za předpokladu perfektního škálování) |
| 64 | 442,578 min | 28325 min |
| 96 | 311,945 min | 29946,7 min |
Pro Intel to bohužel nevypadá moc dobře a odhady pro jeden akcelerátor jsou minimálně 3násobné. Ostatně 96 akcelerátorů potřebovalo 312 minut, zatímco u Nvidie jich to 128 zvládlo za 64 minut (dá se předpokládat, že 96 Nvidií H100 by na to potřebovalo zhruba 85 minut. Každopádně Intel říká, že softwarový update plánovaný na září by měl výkon jeho systémů zvýšit 1,5× až 2×. Pak by měly být podle Jordana Plawnera, ředitele AI části Habana Labs, akcelerátory Gaudi2 konkurencí Nvidii H100 za nižší cenu.