

Společnosti NVIDIA a IBM přicházejí s návrhem nového způsobu komunikace mezi GPU a SSD, který by šel ještě dál než DirectStorage od Microsoftu. Mluvit tu budeme o BaM, čili o Big Accelerator Memory.
Není zrovna jasné, proč je písmeno a ve zkratce BaM malé, ale tak tomu prostě je. Big Accelerator Memory je dítko především NVIDIE a IBM, které má zajistit, aby mohly grafické čipy komunikovat přímo s SSD bez zatížení procesoru i využití speciálního API. Nejedná se tu ovšem o technologii, která by byla určena zvláště pro domácí PC a herní účely, k tomu si sama NVIDIA chystá svou RTX IO, i když v tomto ohledu je v poslední době spíše ticho po pěšině.
BaM se bude týkat především serverů, HPC a práce s obrovskými objemy dat, což odpovídá i výbavě výpočetních akcelerátorů, které už dnes nesou až 128 GB rychlé paměti HBM2e a na dveře už pomalu klepou nové generace. Čím více paměti, tím objemnější data, o která se dnes musí starat také procesor.
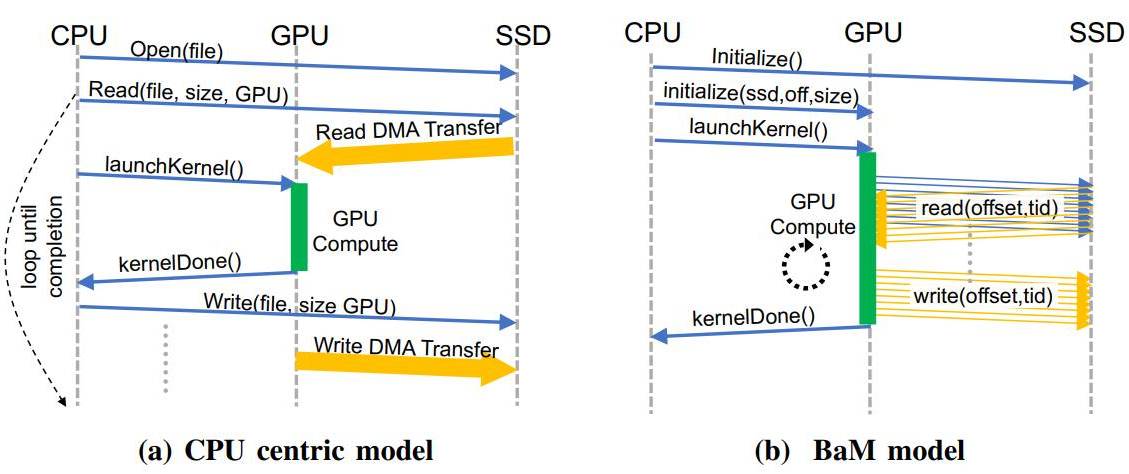
BaM tak má GPU akcelerátorům umožnit, aby samotná data z SSD či systémové paměti získaly už ne prostřednictvím procesoru, i když jak ukazuje model, ten musí celou proceduru inicializovat, čili GPU jej ani tak zcela neobejde, ale to je pochopitelné, nejde o počítačovou anarchii.
Pro dané účely se tu využije pochopitelně rozhraní PCIe a dále pak RDMA (Remote Direct Memory Access) a speciální Linux kernel driver, který umožní akcelerátorům přímo číst a zapisovat z/do SSD. Příslušné požadavky od jednotlivých GPU vláken se budou stavět do fronty, samozřejmě pokud se daná data nenajdou v lokální paměti. Nevyužije se zde přitom překlad virtuálních adres, čili nehrozí TLB miss, apod.
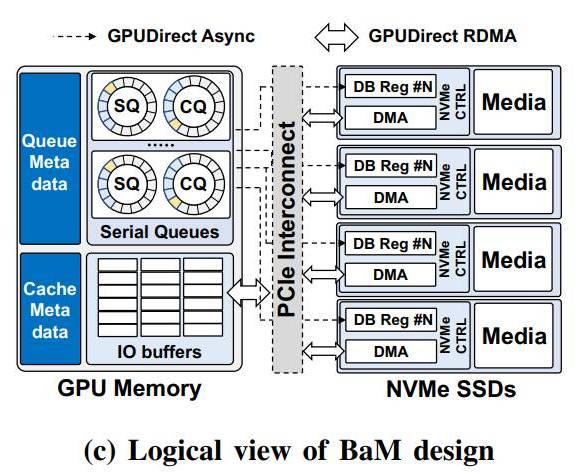
NVIDIA uvádí, že GPU tak bude moci číst či zapisovat menší objemy dat dle potřeby, což může oproti klasickému modelu značně snížit celkový objem přenášených dat s ohledem na jejich amplifikaci. Zkrátka a dobře, přesuny dat budou v rámci BaM přímé a efektivní, neboť do nich nebude vstupovat CPU.
NVIDIA navíc tvrdí, že toto řešení v důsledku dokáže konkurovat i tzv. DRAM-only systémům, které se snaží mít potřebná data k dispozici ve velice objemné systémové paměti, a jako takové jsou pochopitelně velice drahé. To už nebylo více rozvedeno, ale lze předpokládat, že jde o konkurenci z hlediska poměru výkonu a ceny a ne že by model BaM dokázal být rychlejší. Jistě ale bude mnohem lepší z hlediska dostupné paměti, neboť těžko najdeme systém využívající DRAM, která by mohla být objemnější než NAND Flash.
Příslušný ovladač pro BaM bude později vypuštěn do světa v podobě open source.

















